
꺼내먹는지식 준
딥러닝 추천 모델 - 2 (Autoencoder) 본문

주어진 input에 대해서 추론된 reconstructed input 과 차이를 최대한 줄이는 방법으로 loss function 을 구성하고,
이미지 데이터 같은 경우에는 root mean square error, sparse vector 는 softmax 를 loss function 으로 사용한다.
꼭 똑같이 사용하는 것 만이 아니라 노이즈가 있는 이미지를 노이즈가 없는 이미지로 전환하는 등 다양하게 사용된다.

오토인코더의 발전된 형태
일부러 random noise 를 추가하여 강제로 noise 한 입력값을 넣고, noise 가 없는 이미지가 복원되도록 함으로써 더 robust 한 모델이 학습된다. (또한 깨끗한 이미지에만 overfitting 되지 않는다.)
그 이후에도 variational autoencoder 나 conditional autoencoder 등이 등장하였다.
해당 오토인코더는 추천 시스템에 어떻게 활용되는지 살펴보자.

간단하고 논문 길이도 2장
Auto Encoder를 Collaborative Filtering 에 적용하여 user 와 item 에 대한 embedding 을 더 잘 표현하고 복잡도는 줄인 모델
Autoencoder를 활용하여 user 와 item의 embedding으로 좋은 representation을 만들 수 있다.
해당 원리를 사용한 것을 AutoRec 이라 한다.

AutoRec 과 MLP 의 성능 차이를 비교해볼 필요가 있을 것 같다.

기본 Auto Encoder 와 차이가 없다.

기존 $r$ 에 $V$ 라는 encoder weight 를 곱하고 + $\mu$ 라는 bias 를 더한 후, $g$ 라는 activation function 을 씌우게 되면 g라는 값은 representation 값이 되고 representation에 decoder의 $W$ 라는 weight 를 곱하고 $b$ 라는 bias 를 더한 후 activation function $f$를 통과하면 최종적으로 decoder 를 통과한 reconstructed rating 이 구해진다.
실제 rating 과 예측 r 의 차이를 최소화 하는 방향으로 $W, V, mu, b$ 가 학습 된다.
활성화 함수 g 와 f를 Sigmoid 와 Identity function 으로 사용하였다.
※ Sigmoid 함수는 아는데, Identity 활성화 function 는 처음 듣는다.

무려 7년전 논문이기에 간단한 딥러닝 구조를 사용했고 비교 대상이 RBM 과 MF 였다.
node 개수(hidden layer, 즉 표현 차원을 키울 수록)가 늘어날 수록 성능은 향상
좀더 고급 encoder 로 발전시킨 논문들이 추후에 여럿 존재했다.
그중 하나는 Collaborative Denoising Auto-Encoders for Top-N Recommender Systems 이다.

Rating 을 제대로 예측하는 것이 아니라 아이템 선호도를 예측해서 TOP N개 추천

본 논문은 Top-N 추천이 핵심이기에 NDCG와 같은 다른 metric 사용
문제 단순화를 위해 rating 정보를 0 또는 1 정보로 바꿔서 학습 데이터로 사용한다. (그럼 해당 경우 4,5 점만 1 이고 0~3점을 0으로 해야하는가에 대한 의사결정이 선 필요할 것 같다.)

사용자 $u$ 를 기준으로 모든 rating 인 $y_u$ 를 구한 뒤 그냥 사용하는 것이 아니라 $\tilde{y}_u$ 를 사용한다.
$\tilde{y}_u$ 는 q의 확률에 의해 0 으로 drop out 된 벡터
$\rightarrow$ 해당 방법으로 noise 를 준다.
개별 유저 특징의 차이를 $V_u$ 파라미터가 학습하여 Top N 추천에 사용한다. (User Node)
기존 auto encoder와 다른 점은 바로 $\tilde{y}_u$ 를 사용한다는 점과 user 별 특징을 하이퍼 파라미터로 추가해 주었다는 점이다.
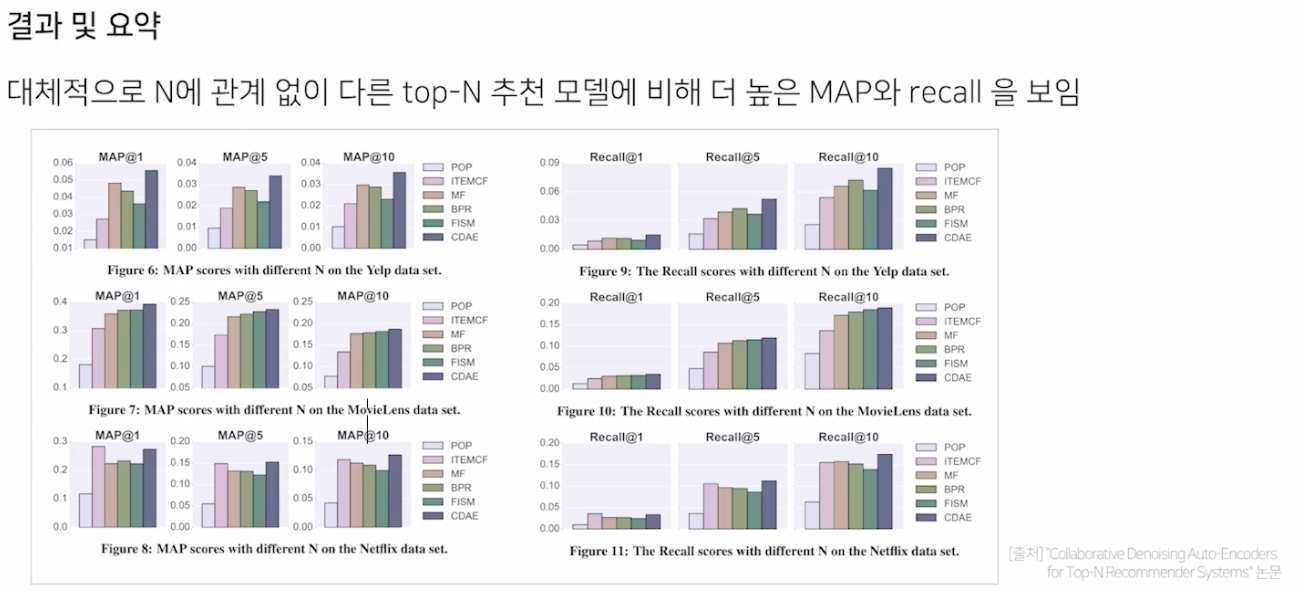
다른 top-N 모델들보다 좋은 성능을 보여주었다.
이 외에도 다른 고급 모델들이 소개되어왔다.
'AI > 추천시스템' 카테고리의 다른 글
| MLP (neural)CF, AutoRec 코드 구현 간단 정리 (0) | 2022.07.26 |
|---|---|
| 딥러닝 추천 모델 - 1 (MLP) (0) | 2022.07.24 |
| ANN (Approximate Nearest Neighbor) (0) | 2022.07.19 |
| Item2Vec (0) | 2022.07.19 |
| Collaborative Filtering - 2 (Model based CF, Matrix Factorization, Bayesian Personalized Ranking) (0) | 2022.07.15 |



