
꺼내먹는지식 준
ANN (Approximate Nearest Neighbor) 본문

주어진 vector space 에서 내가 원하는 query vector와 가장 유사한 vector 를 찾는 알고리즘
추천 모델 서빙 자체는 Nearest Neighbor Search 와 굉장히 유사하다. 모델 학습을 통해 생성된 유저 아이템 벡터를 사용하여 주어진 query vector와 가장 유사도 높은(인접한 이웃) 벡터를 찾아주는 것이 추천 시스템이다.
아주 정확한 Nearest Neighbor 를 찾기 위해서는 Brute Force 가 가장 간단하다.
사실 MF 에서 Brute Force 로 유사도를 비교하는 과정을 보며 그 과정자체가 굉장히 비효율적이라고 느꼈었는데, 이에 대한 문제를 해당 기법이 해결해주는지 한번 잘 참고해고자 한다.
벡터의 차원이 커질 수록 유사도 연산이 오래걸리고, 벡터의 개수가 커질 수록 시간이 선형적으로 증가
→ 당연하게 아 이 bottleneck은 해결할 수 있는 여지가 많구나를 느껴야 한다. 현업에서 사용 불가.
정확도는 약간 포기하고 K 개의 근접한 이웃을 빠르게 계산하자.
다양한 ANN 알고리즘의 성능을 나타낸 그래프이다.
정확도가 높아질 수록 속도가 점점 느려짐을 볼 수 있다. 100%를 고집하지말고 99% 혹은 90%로 시간을 단축해보자. 즉 적절한 balance 를 찾아보자.
ANNOY (Approximately Nearest Neighborhood Oh Yeah)
여러 기법들이 많지만 해당 기법에 좀 더 집중하고 다른 기법들은 간단하게 설명해본다.
(ANNOY는 직접 한번 구현해보면 좋을 것 같다.)
hyperplane
subspace → binary tree
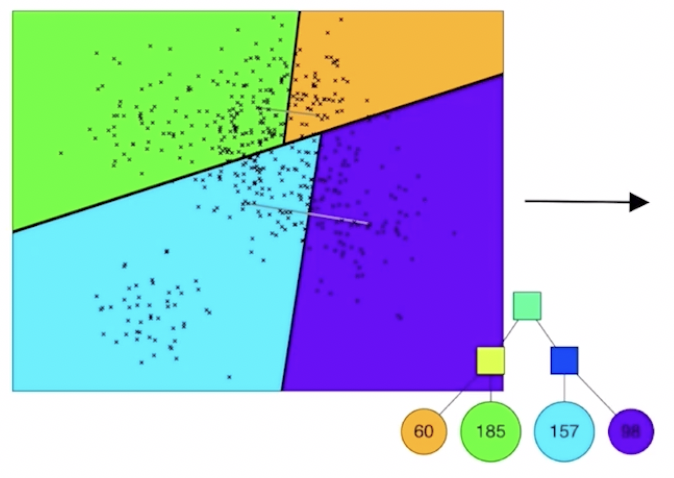
색상 구간에 포함되어 있는 벡터의 개수

각각의 subspace는 binary tree 노드에 해당하고, tree 자료 구조를 통해 해당 노드에 몇개 그리고 어떤 벡터들이 들어있는지 저장
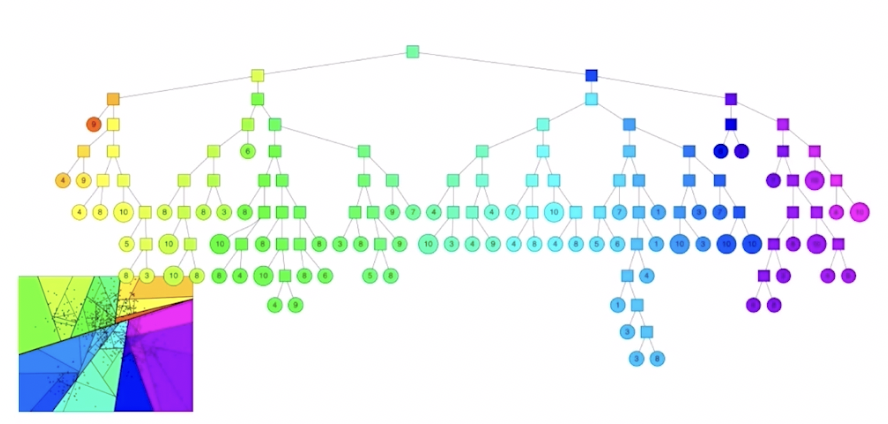
log N 시간 만에 query 벡터가 어디에 있는지 탐색
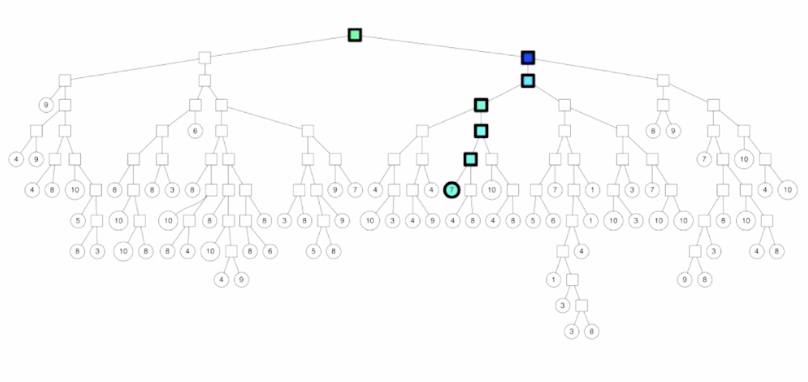
탐색을 마치고 나면, 해당 subspace안의 노드들하고만 유사도 비교
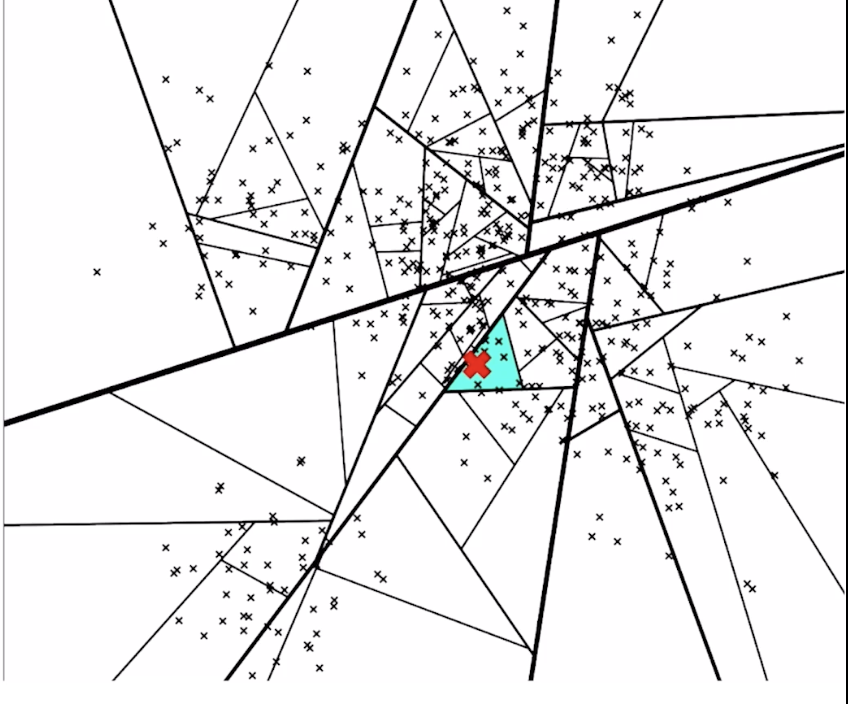

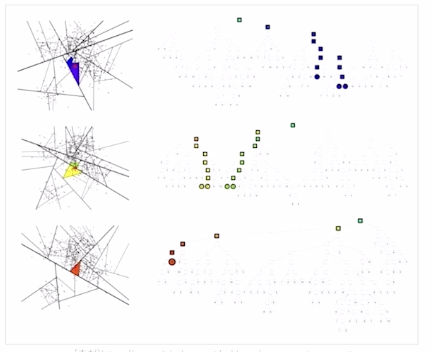
1. priority queue 를 사용하여 물리적으로 가장 가까운 subspace 도 포함하여 검색 (정확도는 올라가지만 탐색 속도는 증가한다.)
2. binary tree 를 여러개 생성하여 병렬적으로 탐색

GPU 지원을 안하는 점이 아쉽. 적은 데이터셋 추천에 적합
새로운 데이터 추가시, ANNOY 를 하기 위하여 전체 데이터로 새로운 트리를 생성해야 한다.
몇가지 이외의 ANN

벡터를 그래프로 표현, 벡터 하나하나가 그래프의 노드, 벡터가 가까우면 edge 로 연결,
Small World Graphs: 전체 벡터 노드들 중에서 물리적으로 가까이 연결된 점들만 연결한 그래프, 즉 멀리있는 벡터 (유사도가 작은) 와는 edge가 연결되어 있지 않다.
Naviagble: Small World graph를 각각 연결해주는 long edge 가 존재. (유사하지 않은) 거리가 많이 떨어져 있는 노드들도 서로 탐색 할 수 있다.
Hierarchical: 계층적으로 만든 것, 결국에는 계층적으로 탐색을 진행해서 ANN 속도 향상 시킴
Layer 0: 모든 node 사용해서 navigable small world graphs 생성
Layer 1: random sampling 을 통해서 일부 벡터만 살려서 layer 1 구성,
Layer 2: Layer 1 에서도 일부만 random sampling 하여 일부 벡터로만 layer 2 구성
해당 그래프의 작동 방식은 위 목차 참고
즉, 샘플링으로 최대한 줄여놓은 상태에서 타겟 노드를 찾는 것. 타겟 노드를 찾으면 타겟 노드 근방에 있었던 노드들만 후보 설정
다른 방법들과 마찬가지로 search space를 줄여서 속도를 빠르게 하는 방법
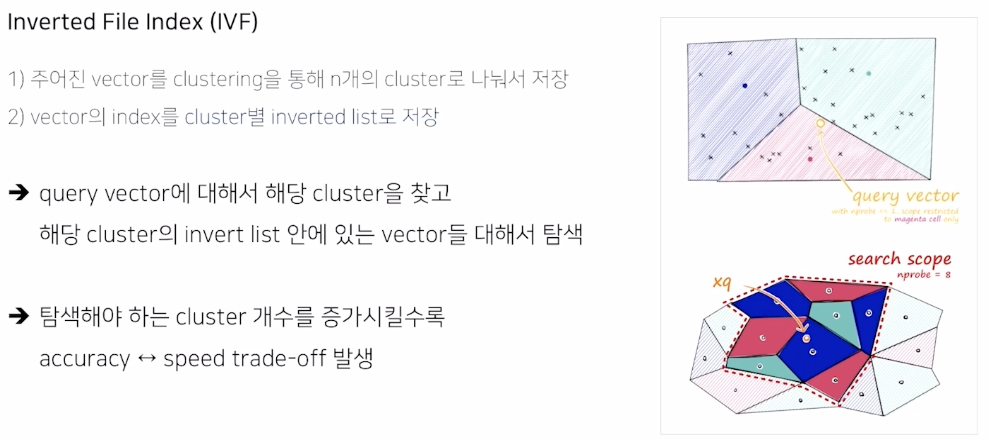
K-means 와 같은 cluster로 전체 vector를 n개로 나눠서 저장
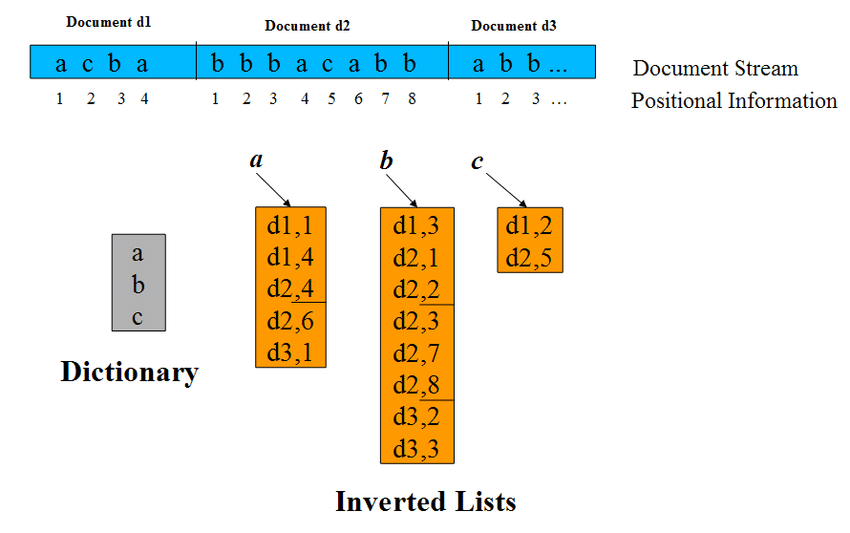
벡터 index를 cluster 별로 inverted list 로 저장

query vector에 대해서 해당 cluster를 찾고, 해당 cluster 의 inverted list안에 있는 vector 탐색
만약 찾고자하는 벡터가 경계 근처에 있는 경우 cluster를 확장해야 한다.
탐색 개수를 증가시킬 수록 정확도는 오르고, 속도는 떨어진다.

search space 를 줄이는 것과는 다른 아이디어
기존 벡터가 가지고 있는 고유한 값들을 압축하여 표현
유사도 연산 자체를 더 빠르게 수행할 수 있도록 한다.
1) N 차원 vector를 M개의 subvector 로 나눈다.
2) 각각의 subvector 군에서 k-means를 진행하여 centroid 를 구한다.
3) 각 subvector가 centroid 로 간략화 된 것을 알 수 있다.
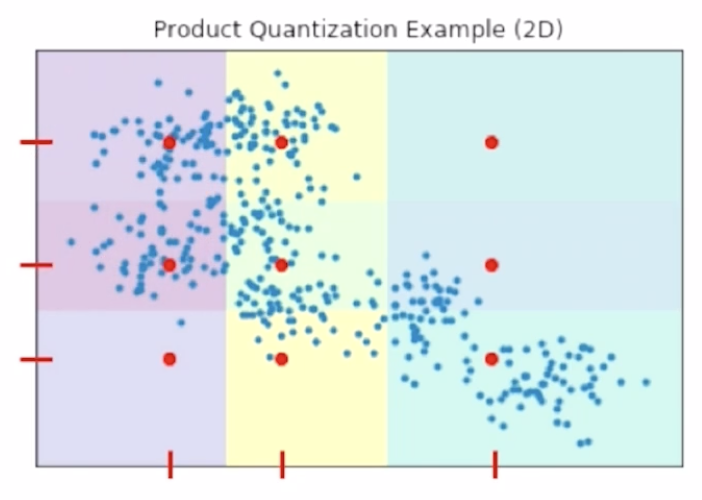
기존 embedding vector의 정확한 값은 잃어버리지만 최대한 centroid 를 통해 유사하게 유지시키고, 유사도 연산이 거의 요구되지 않는다. (O(1))
해당방법인 PQ(product quantization)과 IVF(Inverted File Index) 를 동시 사용해서 더 빠르고 효율적인 ANN 수행이 가능하다.
(faiss 에서는 해당 라이브러리 제공)
'AI > 추천시스템' 카테고리의 다른 글
| 딥러닝 추천 모델 - 2 (Autoencoder) (0) | 2022.07.25 |
|---|---|
| 딥러닝 추천 모델 - 1 (MLP) (0) | 2022.07.24 |
| Item2Vec (0) | 2022.07.19 |
| Collaborative Filtering - 2 (Model based CF, Matrix Factorization, Bayesian Personalized Ranking) (0) | 2022.07.15 |
| 고윳값, 고유벡터 (eigen value, eigen vector) (0) | 2022.07.12 |



