
꺼내먹는지식 준
딥러닝 추천 모델 - 1 (MLP) 본문
딥러닝 추천 모델의 장점

한마디로 사람을 통해 직접 하기 어려운 학습이 가능하다.
사람들은 수식의 단순화 등의 여러 이유로 인해 data의 선형성을(선형가정) 통해 모델을 만들곤 한다.
하지만 딥러닝은 tanh, relu 등의 non-linear activation 을 통해 non-linearity 를 효과적으로 학습 가능하다.
또한 사람이 직접 찾아야 하던 feature 을 모델이 데이터로부터 직접 학습하므로 사람이 찾지 못한 feature도 효과적으로 학습한다.
(많은 연구가 이뤄지지 못한 분야에도 바로 적용이 가능하다.)

특히나 자연어, 음성 같이 sequence modeling 에서 강력한 성능을 보인다고 한다.
추천 시스템에서 next-time prediction(현재까지 소비한 아이템으로 다음 아이템 예측), session-based recommentation(같은 세션에서 추천 수행) 과 같은 분야에 효과적 적용 가능하다.
여러 프레임 워크가 존재하여 연구, 개발 현업에서 적극 활용 가능하다.
최신 기법 모델들은 대부분 딥러닝 기반이다.
MLP (multi layer perceptron)
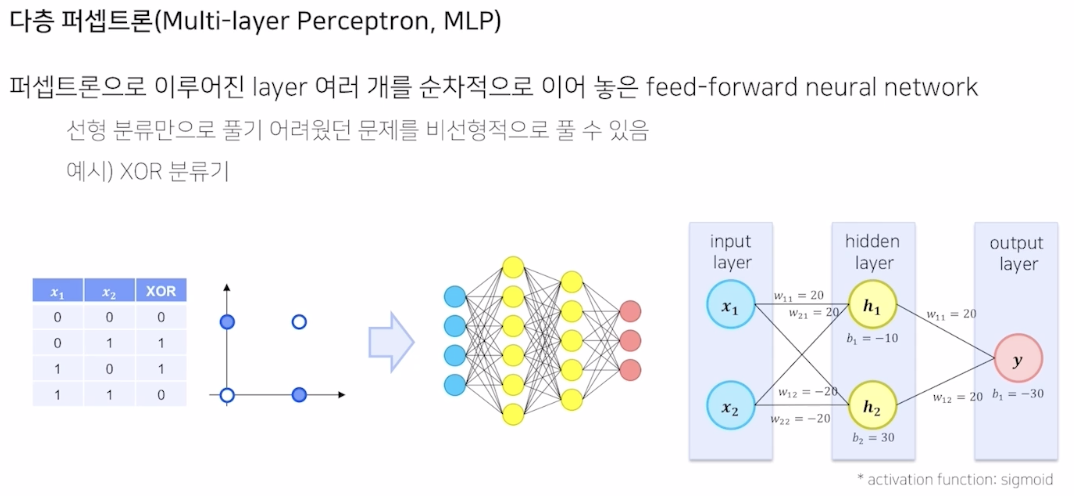
※ 퍼셉트론: 입력(들)에 대해 weight 를 적용한 후 activation function 을 통과시켜 새로운 결과값을 얻는 방법

MF에 MLP 를 처음 제시

$r_{u,i} = p_u^T \cdot q_i$
유저와 아이템 사이의 복잡한 관계를 표현해야 하는데 해당 linear 한 interaction은 표현력에 한계를 갖는다.
$u_4$ 를 보자, 해당 아이템이 벡터공간에 표현이 되면 가장 가까운 $u_1$ 의 latent space인 $p_1$과 $p_4$와 가깝다.
그다음으로는 $u_3$ 에 대응되는 $p_3$와 가까워야 하나, 오히려 $u_2$ 인 $p_2$와 더 가깝다.
이 때 최종 dot product 를 진행하면 당연히 $p_2$가 $p_3$ 보다 더 유사하다고 판단한다.
어떻게 해도 $p_1$과 가까운 $p_4$는 $p_3$ 와 가까워질 수 없다.
이러한 문제를 해결하기 위해서는 latent space 를 더 큰 차원으로 표현해서 유사도 문제를 해결할 수 있지만, 계속해서 차원을 키우다보면 overfitting 문제가 발생한다.
이에 따라 해당 논문에서는 모델에 non linear 를 추가하여 즉 MLP 를 추가하여 해당 문제를 해결했다.

간단하다 one hot encoding 의 user, item vector 를 넣고
embedding layer로 latent vector 화 한 후,
neural Layer 를 통과시키고 최종 예측 값과 실제 값을 비교하여 학습한다.
activation function을 logistic 또는 probit 함수를 쓰는 이유는 잘 모르겠다. 그냥 sigmoid 쓰면 안되나?
(skip gram보다 더 직관적이고 쉽지만 좋은 점은 non linearlity 학습)

상단 이미지에서 우측의 녹색이 MLP layer 이고, 좌측은 기존의 MF 의 일반화(generalized) 표현이다. (hereafter, GMF)
GMF layer 는 user item 을 각각 MF user vector 와 MF Item Vector 로 embedding 한 후 element wise product 로 GMF 값을 구한다. 오른쪽 부분은 MLP user, item embedding을 사용하여 concatenate 한 후 그 위로 feed forward 한다.
각각 layer 의 output 을 최종적으로 concat 하여 타겟값과 y hat 을 구하여 모델을 시킨다. (최종 layer sigmoid 사용)
해당 방법은 일종의 앙상블 기법이다.
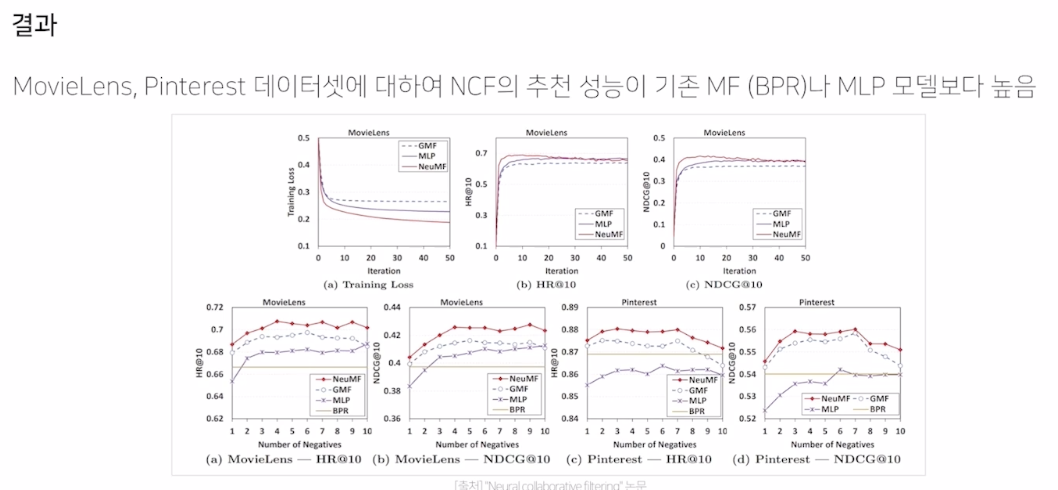
앙상블한 NCF (neural matrix Factorization model)
성능이 약간 더 높다.
논문이 큰 성능 향상 보다는 MLP 를 처음 추가했던 논문이다. (MF 대비 MLP의 단점 확인 필요)

실제 유튜브 사용 알고리즘

3가지 어려움이 있다.
1) Scalability
유저와 아이템의 큰 수로 인해 학습한 모델을 효율적으로 서빙해야한다.
2) Freshness
기존 학습 된 컨텐츠와 새롭게 추가되는 컨텐츠를 적절히 조합해야 한다.
- rule base 만으로는 해당 부분 해결에 한계가 있어서 모델이 해당 부분을 표현할 수 있도록 설계
3) Noise
큰 노이즈에 대해 모델이 잘 대처해야 한다.
유저와 아이템의 개수가 워낙 많기 때문에 데이터는 sparse 해진다. 또한 youtube 는 외부 요인이 존재하여 구독 좋아요 같은 explicit feedback 만 사용하면 유저 행동 예측이 어렵다. 유저가 어떤 영상을 봤다, 얼마만큼 봤다와 같은 implicit data 를 잘 가공해서 사용해야 한다.

위 언급된 3가지 문제를 해결하기 위하여 다음의 두가지 방법을 제안한다.
(논문의 핵심)
1. 많은 비디오 중 "주어진 사용자"에 해당하는 (수백개)Top N 개의 추천 아이템 생성
2. 최종 추천 대상에 대하여 최종 랭킹 선정
랭킹을 선정할 때는 이미 아이템이 수백개로 줄어든 상태이기에 유저, 비디오 피쳐를 더 풍부하게 사용하여
정확한 스코어를 구하고 최종 추천 리스트를 제공하였다.
아래에서 좀 더 자세히 설명한다.
1. Candidate Generation
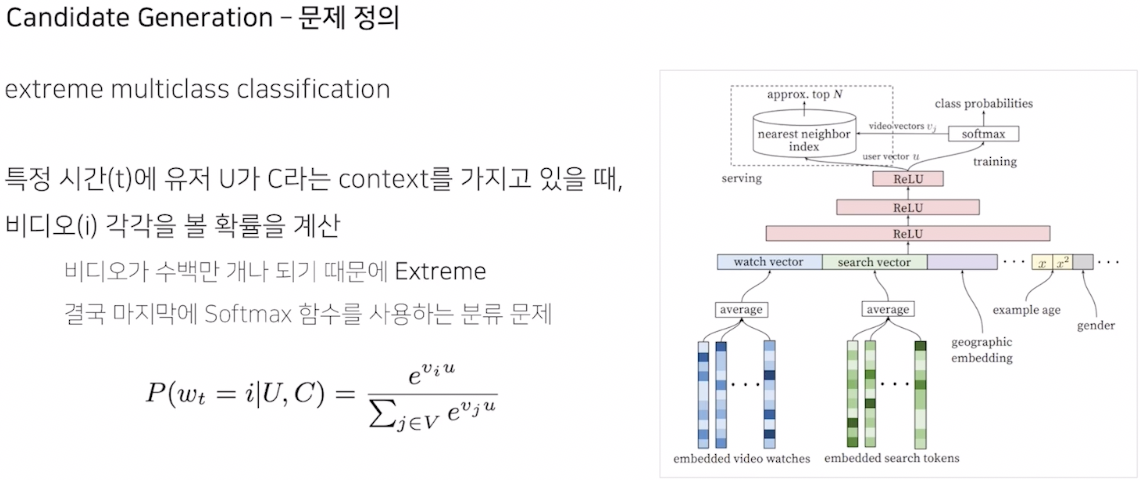
비디오가 수백만 개나 되기 때문에 EXTREME 한 multiclass classification
분류문제이기는 하나 굉장히 severe한 규칙


시청 로그가 얼마나 지났는가에 따라 example age 값으로 구성
과거 데이터는 덜, 최신 데이터는 더 많이 학습되도록 하여 feature를 예측의 input으로 사용
$\rightarrow$ Bootstraping 현상 방지

dense layer (feed forward)
최종적으로 multiclass classification (softmax function)

수백만개의 비디오 가운데서 수백개의 비디오를 생성하는 과정을 어떻게 "서빙" 해야 하는지에 관한 내용
수백만개중 수백개를 추출하는법
수백만개의 비디오 전체에 대해 모든 softmax probability 를 계산하고 그 중에 가장 probability가 높은 N개를 추출해야한다.
수백만개의 내적을 구하는 건 굉장히 많은 시간 소요, 실시간 서빙이 거의 불가능하다.
Annoy, Faiss 같이 주어진 벡터와 가장 유사한 벡터를 빠르게 찾아주는 ANN (Approximate Nearest Neighbor)라이브러리를 사용하여 빠르게 서빙한다.
해당 방법을 통해 정확한 softmax 는 아니지만 주어진 유저벡터와 최대한 유사한 수백개를 서빙하는 방식
Ranking

구한 수백개의 probability 를 바로 ranking 으로 사용하면 정확도가 많이 떨어지는 걸까? 라는 생각을 했지만, 수백만개에서 수백개로 먼저 추린 후, 더 많은 feature 를 사용하여 정밀성을 높히는 방식이 타당한 것 같다.
'가중치에 시청 시간을 포함' : 유튜브 볼 때 자주 클릭한 것 보다 오래본게 추천에 뜨는 걸 느끼고 있었는데 해당 느낌과 동일한 결과

어떤 feature 가 좋은지 data scientist 들이 잘 확인하고 가공하는 부분이 선재로 필요하다.
모델 자체가 보다 서비스에 맞는 feature를 잘 찾아 구성하는 것이 더 중요하다.

weighted cross-entropy loss (많이 보았는가 안 보았는가에 따라 weighted 를 주어 학습)
오래보았을 수록 더 만족했기 때문에
클릭 후 바로 떠나는 건 weight 0 에 가까워서 loss에 반영이 거의 안된다.

현업에서의 serving 까지 고려한 기념비적 논문
여러 유저 feature 사용, 아이템의 최신성을 위한 Example Age 까지 사용
Ranking 에서 트리 보다 딥러닝 모델이 더 뛰어난 성능 보여줌
(다양한 feature, 단순 CTR 이 아니라 Expected Watch Time 고려하였기에)
'AI > 추천시스템' 카테고리의 다른 글
| MLP (neural)CF, AutoRec 코드 구현 간단 정리 (0) | 2022.07.26 |
|---|---|
| 딥러닝 추천 모델 - 2 (Autoencoder) (0) | 2022.07.25 |
| ANN (Approximate Nearest Neighbor) (0) | 2022.07.19 |
| Item2Vec (0) | 2022.07.19 |
| Collaborative Filtering - 2 (Model based CF, Matrix Factorization, Bayesian Personalized Ranking) (0) | 2022.07.15 |



