
꺼내먹는지식 준
Item2Vec 본문
임베딩이란?
주어진 데이터를 낮은 차원의 벡터로 만들어서 표현하는 방법

Dense Representation은 Sparse Representation을 훨씬 작은 차원으로 효과적으로 표현할 수 있도록 한다.
Item2Vec 을 이해하기 위하여 먼저 Word2Vec을 살펴보자.

예전에 Word2Vec 을 공부해보며 관련 내용을 정리한적 있다.
https://blog.naver.com/ha_junv/222285855664
Word2Vec (word embedding)
Word 임베딩에 관련해서는 웬만한 교수님 강의를 보는 것보다, 해당 글을 읽는 것이 더 직관적인 이해에 ...
blog.naver.com
https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/11/embedding/
빈도수 세기의 놀라운 마법 Word2Vec, Glove, Fasttext · ratsgo's blog
안녕하세요. 이번 포스팅에서는 단어를 벡터화하는 임베딩(embedding) 방법론인 Word2Vec, Glove, Fasttext에 대해 알아보고자 합니다. 세 방법론은 대체 어떤 정보를 보존하면서 단어벡터를 만들기에 뛰
ratsgo.github.io
사실 내글보다 이 글을 보는 걸 추천
아무튼 Word2Vec은 NLP 공부함에 있어 가장 흥미로운 시작으로 좋은 기억이 있다.
간단한 정리는 아래와 같다.



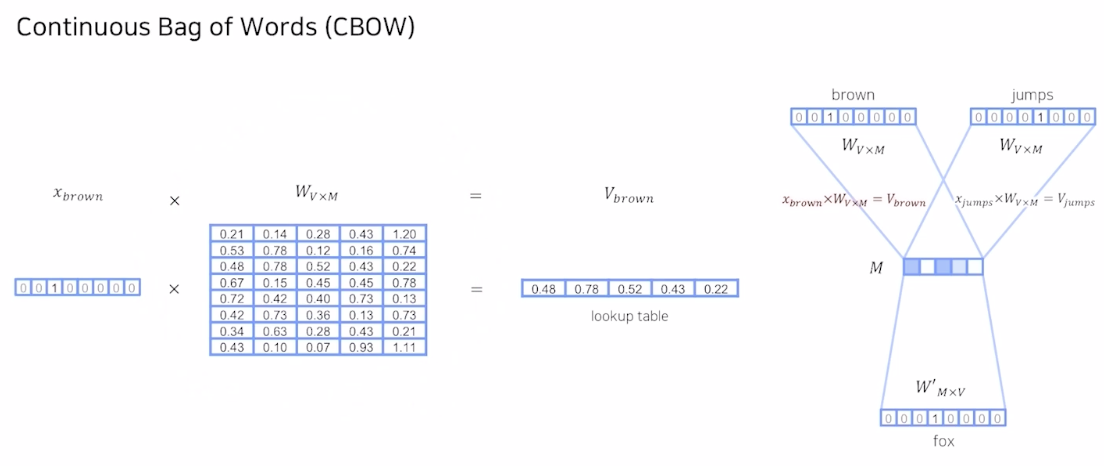
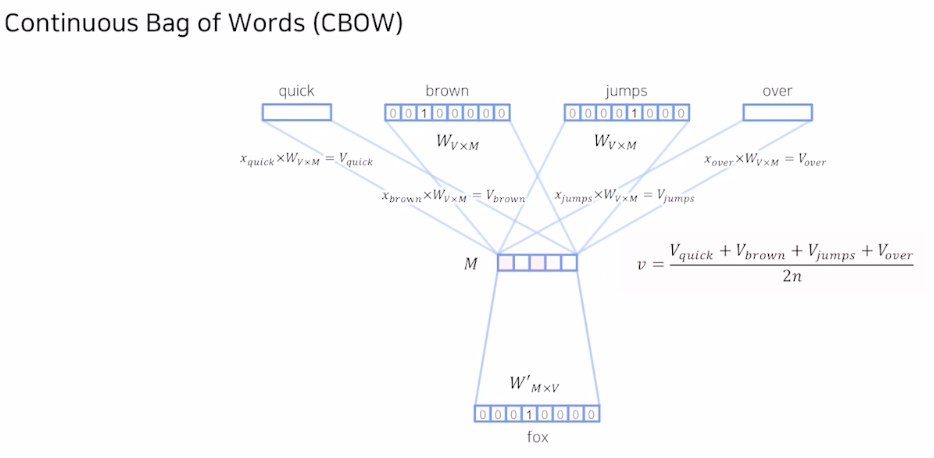
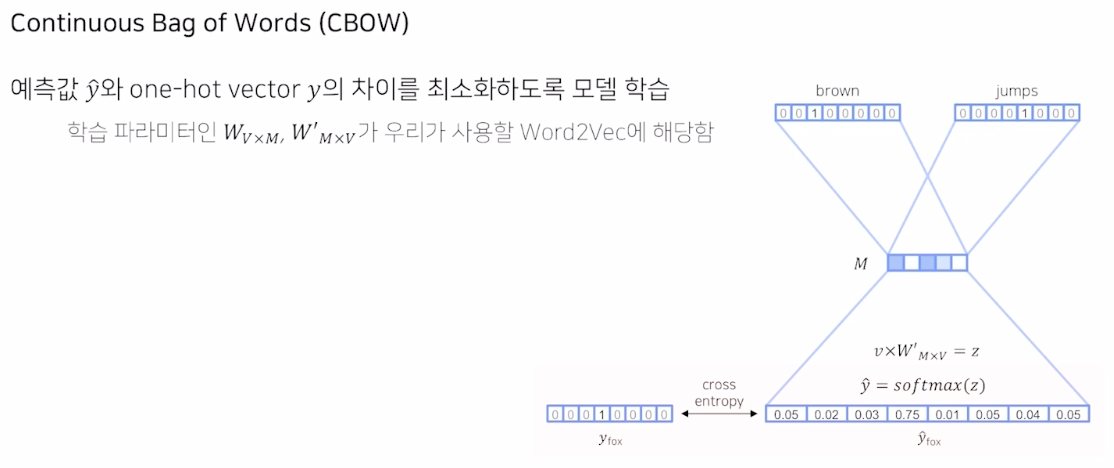
주변에 있는 단어로 중심 단어 예측 방식: 간단하게 각 단어의 embedding 의 평균으로 output을 예측
Skip-gram
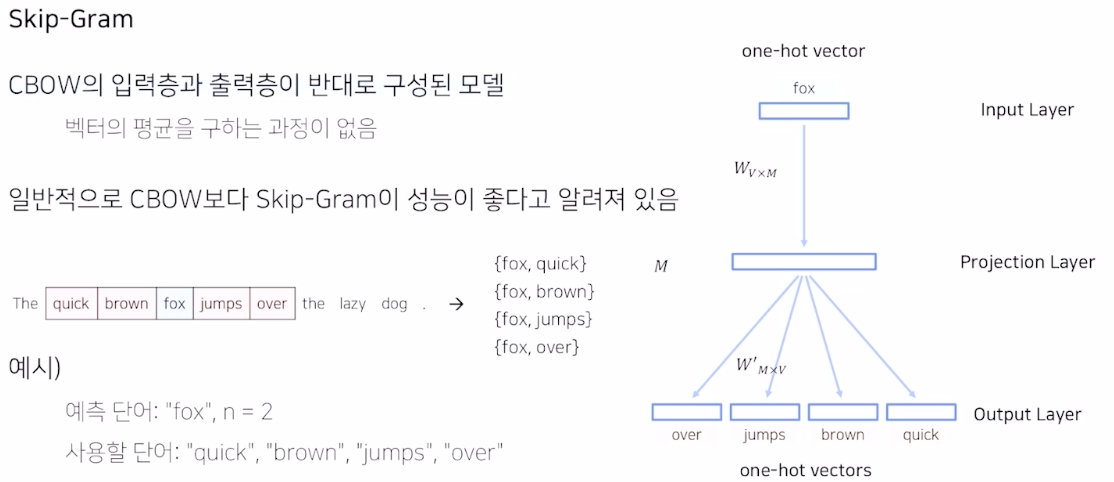
생각 못했던 관점인데 CBOW 와 입력층, 출력층이 반대로 구성되어 있다.
주변에 있는 단어로 중심 단어를 예측하도록 학습시키는 것보다는 Skip-gram 방식으로 학습하는 것이 더 여러번 학습시킬 수 있어 성능이 좋다. 근데 직관적으로 생각해도 그게 더 단어에 대해 입체적으로 이해할 수 있을 것 같다.
전에 학습할 때는 Skip-gram 에 negative sampling 을 더한 기법은 못봤었는데, 이제는 Skip-gram 에 negative sampling 을 더한 기법도 나왔다. 흥미롭다. 이 방법이 Item2Vec 과 관련 깊으니 유심히 살펴보자.
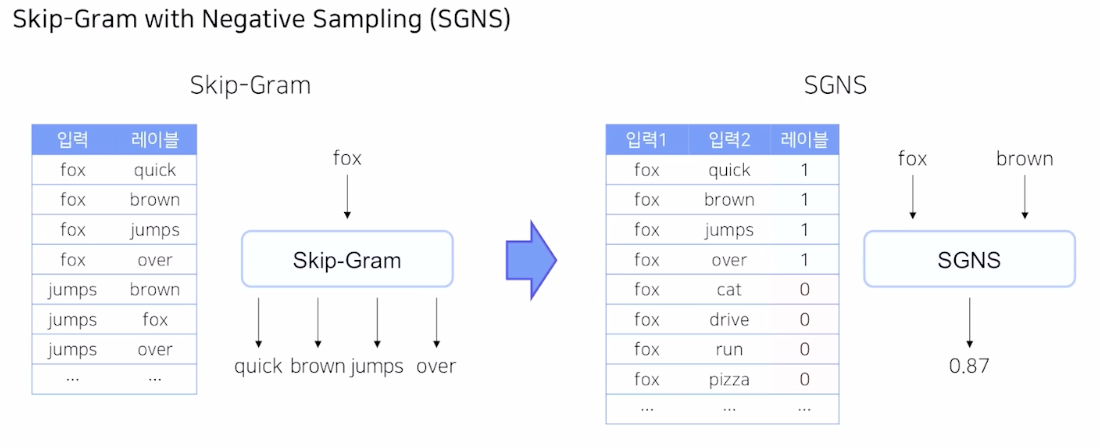
Skip gram 은 주어진 입력 단어에 대해서 주변 단어를 예측하는 multi classes claasification 문제이다.
하지만 Skip gram Negative sampling 에서는 input 과 output을 조금 바꿔서 다른 문제를 구성하였다.
원래 입력과 label 의 값을 모두 입력 값으로 바꾸고, 주변에 있다면 1 주변에 없다면 0을 예측하는 binary classification 문제로 바뀌었다. multi classes classification $\rightarrow$ binary classification 으로 바뀌었기 때문에 모델 구조도 수정되어야 한다.
가운데 있는 단어로 주변에 있는 단어를 예측하는 것이 Skip gram 이었다.
SGNS 로 바뀌면서 둘다 입력값으로 수정되었고 주변에 있는 경우만 1로 예측한다.
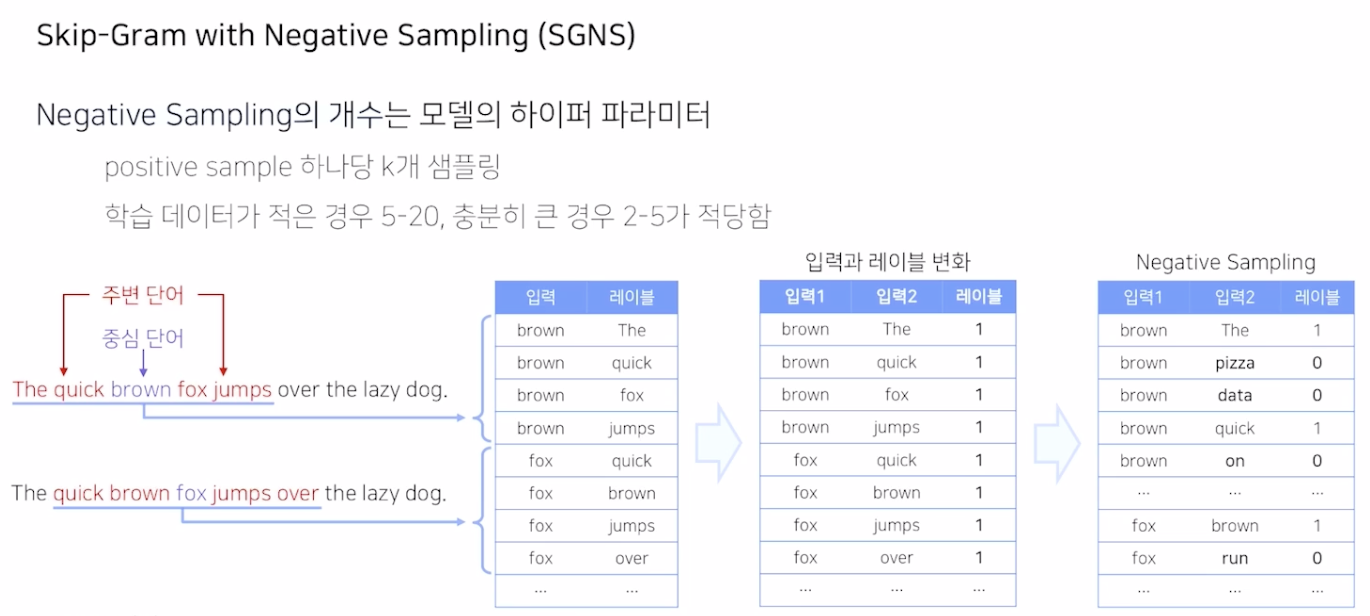
기존 입력과 레이블을 SGNS 형식으로 수정하면 label은 1만 존재한다. (모두 주변에 있는 단어이므로)
이에 따라, 가운데 있는 단어를 중심으로 주변에 있지 않은 단어를 강제로 sampling 하고 label에 0을 준다.
해당 Negative sampling의 수가 Hyperparameter이다.
학습 데이터의 양에 따라 sampling의 수가 바뀐다.

입력 1과 입력 2가 서로 다른 embedding layer 를 갖는다.
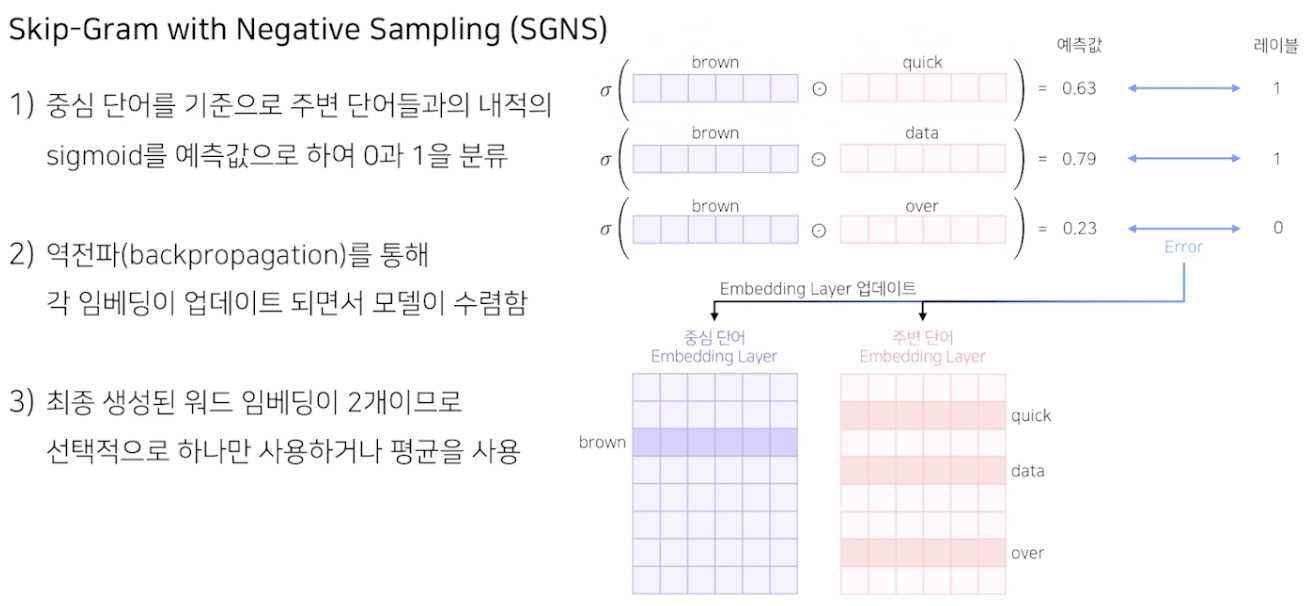
input 1 과 input 2 의 차원은 같으므로 내적을 통해 최종 예측값을 찾을 수 있다.
최종 예측값은 실수값이기 때문에 sigmoid 로 [0,1] 사이로 출력되도록 한다.
실제 레이블과 예측값의 cross entropy 로 loss 를 구해서 back propagation을 수행한다. 이로써 각각의 입력 1과 입력 2 의 matrix 을 업데이트 하고 최종적으로 모델이 과정 속에서 수렴하게 된다.
생성된 word embedding 은 각각 생겨서 2개이고 둘중 하나만 사용해도 되고 둘의 평균을 사용해도 된다.
(성능 차이는 거의 없다.)
모델이 수행한 task 는 binary classification 이지만, 실제 word2vec 의 학습 결과물은 예측 모델 전체가 아니라 학습된 word embedding 이고 이 것이 우리가 구하고자 한 것이다. 이를 이제 적절한 down stream task에 사용한다.
Item2Vec
이제 드디어 Item2Vec 을 공부할 준비가 되었다. Item2Vec은 SGNS에서 영감을 받아 아이템 기반 CF 에 Word2Vec을 적용한 것이다.
word 대신에 item을 embedding 한다.
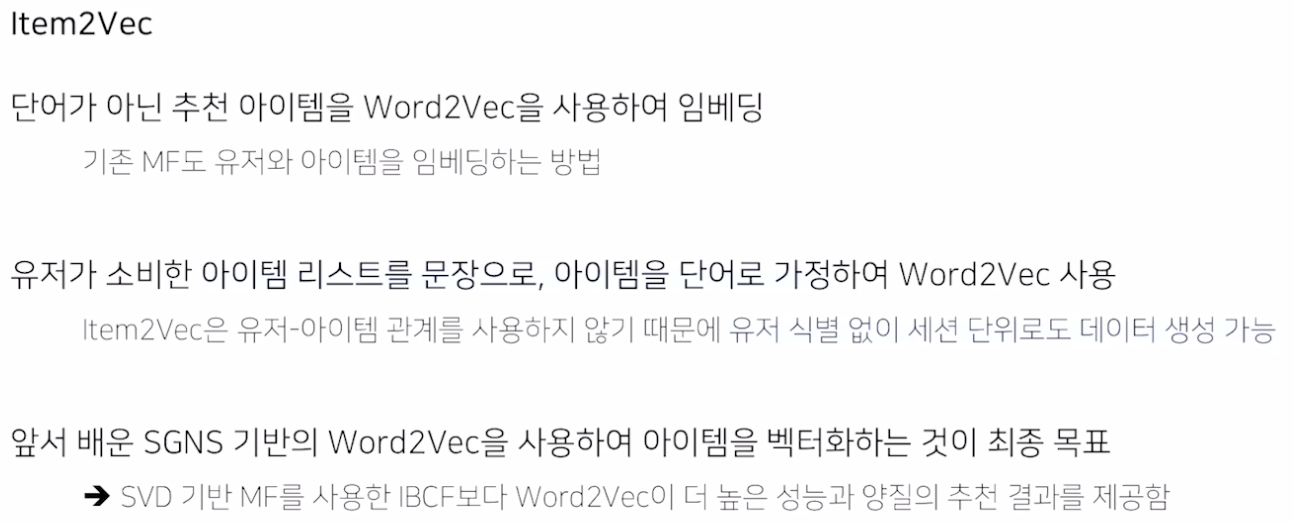
문장: 아이템 리스트
아이템: 단어
즉 유저- 아이템 관계를 사용하지 않기 때문에 개별 유저가 소비한 아이템들만을 학습 데이터로 사용한다.
때로는 그냥 어떤 아이템을 소비했는지에 관한 데이터로도 학습이 가능
결국 아이템을 벡터화하여 기존 MF embedding보다 더 좋은 양질의 추천 결과를 제공한다고 한다.

NLP 문장과 다르게 아이템은 순서가 중요하지 않다.
이로 인해 집합을 사용한다.
대신 집합 안에 존재하는 아이템은 서로 유사하다고 가정한다. (세션별로 시퀀스의 의미가 조금씩 다르기 때문에)
아이템 집합 내 아이템 쌍들은 모두 SGNS의 positive sample 이 된다.
예시를 통해 살펴보자.
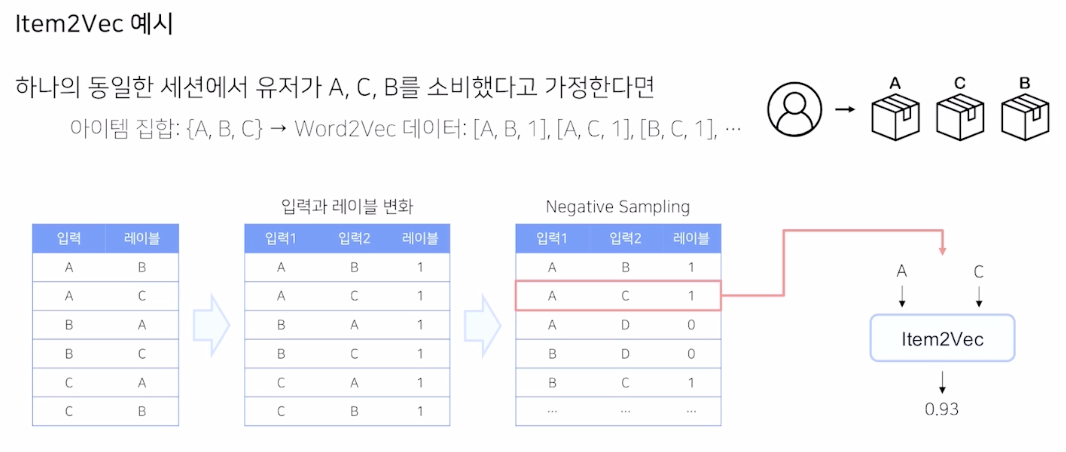
한 유저가 동일 세션에서 A,C,B 를 소비했다고 가정한다. 이때 A,B,C 의 순서는 중요하지 않다.
다만 해당 집합으로 만들 수 있는 조합 6개에서 positive sample 을 만든 이후에, negative sampling 을 통해서 A,B,C 와 다른 조합 D 같은 전체 데이터를 구성하고 해당 데이터로 item2vec 모델을 학습한다.

여기서 SVD 는 MF 를 의미
두 모델의 벡터의 임베딩을 2차원으로 축소하고 시각화하여 비교
카테고리는 모델이 정의하는 것이 아니라, 사람이 이미 정해놓은 "상품 카테고리, 음악 장르 등" 를 의미한다.
같은 카테고리는 같은 색을 갖도록 하였다.
비슷한 카테고리를 갖는 점끼리 모여있는 것이 우측 MF 보다 왼측 Item2Vec이 더 좋은 표현을 나타내는 것을 보여준다.
정량적이지 않아도, 경향성 보기 좋다.
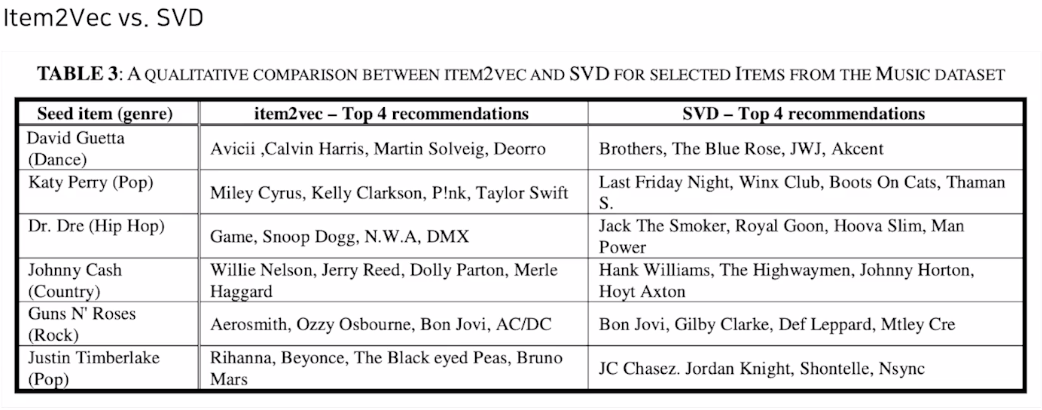
주어진 아티스트와 더 비슷한 아티스트를 찾는 테스크에서 Item2Vec 이 더 효과적이었다.

어떻게 문장과 단어를 구성하는가가 각각의 서비스에서 추천을 잘하는 노하우이다.
'AI > 추천시스템' 카테고리의 다른 글
| 딥러닝 추천 모델 - 1 (MLP) (0) | 2022.07.24 |
|---|---|
| ANN (Approximate Nearest Neighbor) (0) | 2022.07.19 |
| Collaborative Filtering - 2 (Model based CF, Matrix Factorization, Bayesian Personalized Ranking) (0) | 2022.07.15 |
| 고윳값, 고유벡터 (eigen value, eigen vector) (0) | 2022.07.12 |
| Collaborative Filetering - 1 (Neighborhood-based CF, K- Nearest Neightborhood CF) (0) | 2022.07.11 |



