
꺼내먹는지식 준
AutoGrad 본문
Saliency map 을 구하기 위한 구현적 detail
class score에서 graident를 구해서 input domain 의 gradient 를 구하는 것이 최종 목표
input domain 의 gradient를 구하는 것이 최종 목표 back prop된 graident accumulation $\rightarrow$ visualization

gradient구하는 법
Autograd
Automatic Gradient calculating

기본적으로 딥러닝 library도 행렬 연산이나, 기존 행렬 연산들과 다른점이 바로 auto grad
forward, backward pass가 가능하다.
gradient 계산을 쉽게 하도록 해준다.
과거에는 forward 계산을 일일이 손으로 계산하고, backward gradient 수식을 손으로 전개하고 일일이 그려줬다.
현재는 computational graph를 통해 간단하게 구현 (허들이 낮아졌다.)
computational graph는 종말 단 L 이 계산되기까지의 계보를 따로 다 저장하여 다 가지고 있다.
back prop 시, 예를 들어 L부터 a 까지의 graident를 구하고 싶다할 때, L 부터 타고타고 a로 오는 형태로 back prop 을 계산한다. (chain rule)

여지껏 y가 계산된 모든 연산을 back prop 하는 것
$\frac{\partial y}{\partial x}$
x에 대한 미분이면 사실 3이 나와야 할 것 같은데 결과값은 300, 0.3 이 나왔다.
그 이유는 backward의 arguement로 grad가 들어갔기 때문이다.
https://tutorials.pytorch.kr/beginner/blitz/autograd_tutorial.html
torch.autograd 에 대한 간단한 소개 — PyTorch Tutorials 1.10.2+cu102 documentation
Note Click here to download the full example code torch.autograd 에 대한 간단한 소개 torch.autograd 는 신경망 학습을 지원하는 PyTorch의 자동 미분 엔진입니다. 이 단원에서는 autograd가 신경망 학습을 어떻게 돕는
tutorials.pytorch.kr
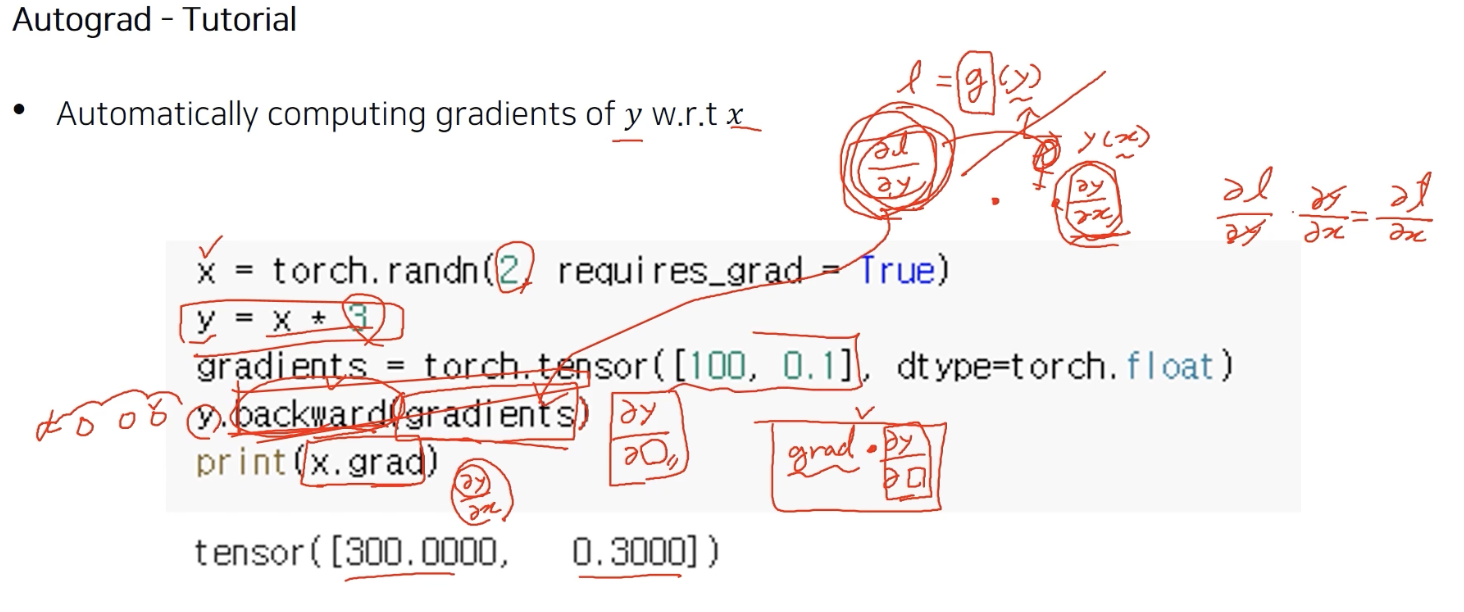
backward에 인자로 gradient를 주었더니 결과가 3이 아니라 다음과 같았다.
미분 값이고 행렬이 아니면 그냥 gradient를 안 넣어줘도 된다.
requires_grad = True gradient 저장 가능 False 저장 불가능
backward 를 두번 호출하면 두번의 미분 값이 중첩된다.
그때 Run time error 가 발생한다. backward 내부의 동작은 중간에 계산 했던 computational graph를 다 저장해놓지 않는다. (너무 무거워서) 이를 통해 메모리를 아낀다. 즉 backward 한번 호출 후 그래프를 다 날린다. 그렇기에 backward를 두번 호출하고 싶으면 retain_graph = True로 설정해야한다.

그결과 두번 call이 accumulation을 하는 것을 관찰 가능!
Grad_fn
computatinoal graph가 grad_fn 안에 구현되어있다.
w,y,z를 출력해보자. w 의 경우 grad_fn = AddBackward0
즉 오른쪽 그림과 같이 x, y의 합으로 grad_fn 이 구현되어있다.


하나의 변수가 computational graph를 가지고 있는 원리는 바로 grad_fn 이다.
Class activation mapping CAM 계산시, 중간에 gradient 를 store 했어야 하는데, 어떻게 하는 걸까?
보통은 Hook을 사용한다.
hook: register forward hook
register_hook을 통해 functing 을 hooking 할 수 있다.
function call을 했을 때 두개의 component 사이에 왔다갔다 하는 메시지를 intercepting하는 것이 일반적인 hook이라고 한다.
여기서 hook은 backward 가 call 될 때 backward 중간에 있는 정보를 꺼내오는, 낚아채는 역할이다.
gradient 를 계산할 때 마다 그 값을 낚아채올 수 있는 function이다.


다음과 같은 model 이 있다고 하자.
hook을 사용하기 위해서는 signature of hook function을 정의해야 한다.

다음의 동작이 수행되도록 구현.
input, output argument
input ,ouput 타입 출력
hooking을 어디서 할까?
hook을 걸고 싶은 layer에다가 hook을 걸어준다.

Feed forward 할 때 hooking 발생하시킨다할 때 다음과 같이 정의하고
activation 이 계산시 conv1 layer 가 계산되어 forward 될 때 hook function 동작하도록 등록


여기서 input, output을 바꾸는건 안된다.
다만 선택적으로 return 을 바꿔서 새로운 gradient를 계산해서 넣어줄 수는 있다.
그러면 backprop 에 반영된다.

자동으로 activation map 을 구할 때 hook 이 동작

hook 이 필요 없을 때는
h.remove() 하면 지워진다.
grad cam 구현시 hook 사용하면 되는데, 중간에 activation map을 가져오는 방법은?
save_feat = [] 전역 변수 다른 곳에서도 참조 가능하도록


'AI > CV' 카테고리의 다른 글
| Object Detection 개괄 from selective search to SSD (0) | 2022.03.13 |
|---|---|
| FC layer 를 1X1 Convolution 으로 바꾸기 (0) | 2022.03.12 |
| CNN Visualization (0) | 2022.03.11 |
| Semantic segmentation (0) | 2022.03.10 |
| semantic segmentation, Detection (0) | 2022.02.08 |



