
꺼내먹는지식 준
Object Detection 개괄 from selective search to SSD 본문
해당 글은 Object Detection에 관련된 총 정리 글이다.

추후 Selective Search, Faster R CNN, Mask R CNN, Single Shot Multi-box Detector, Yolo 정도는 개별글을 올릴 예정이다. SSD 의 리뷰는 해당 글에 그냥 담았다 ㅋ.

Instance segmentation 은 같은 사람도 서로 다른 개체로 구분 가능하고, Semantic segmentation은 불가능하다. (instance는 구분하는 한가지 task를 더 해야한다.)
Panoptic segmentation 은 instance segmentation을 포함하는 더 큰 기술.
이러한 instance를 인식하는 기술이 object detection
Object detection
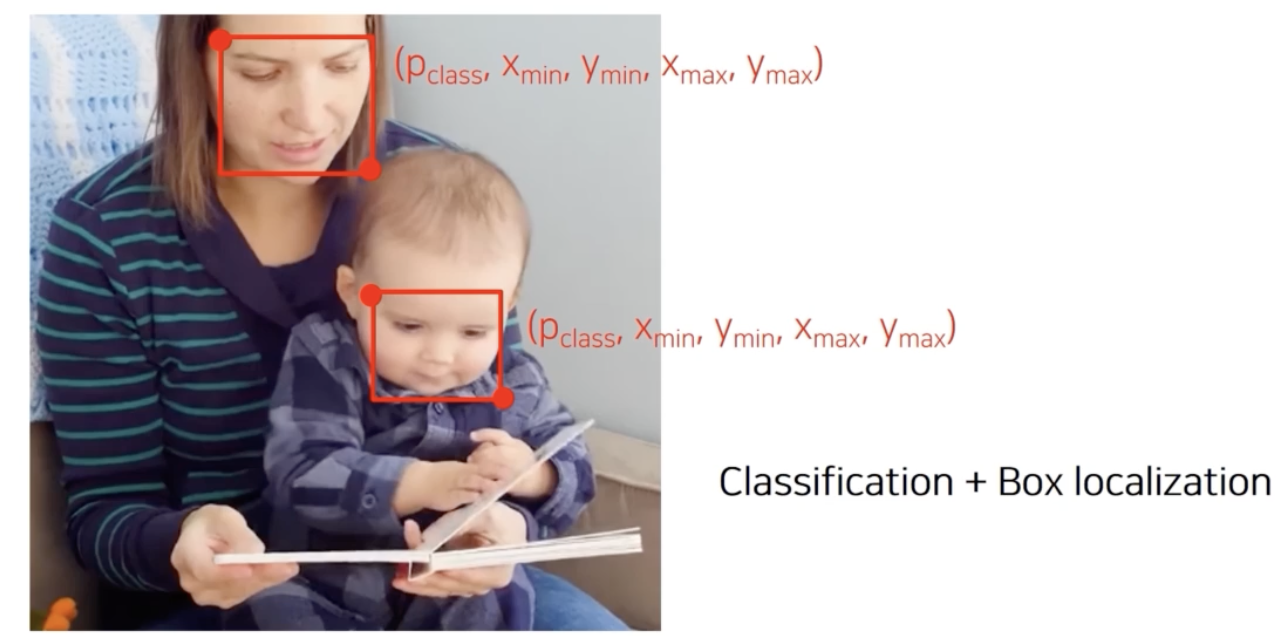

($x_{min}, y_{min}, x_{max}, y_{max}$)Bounding Box 찾기 + Classification
Autonomous Driving, OCR(글자 위치 특정)와 같은 곳에 사용 된다.
과거의 Object Detection
Gradient-based detector
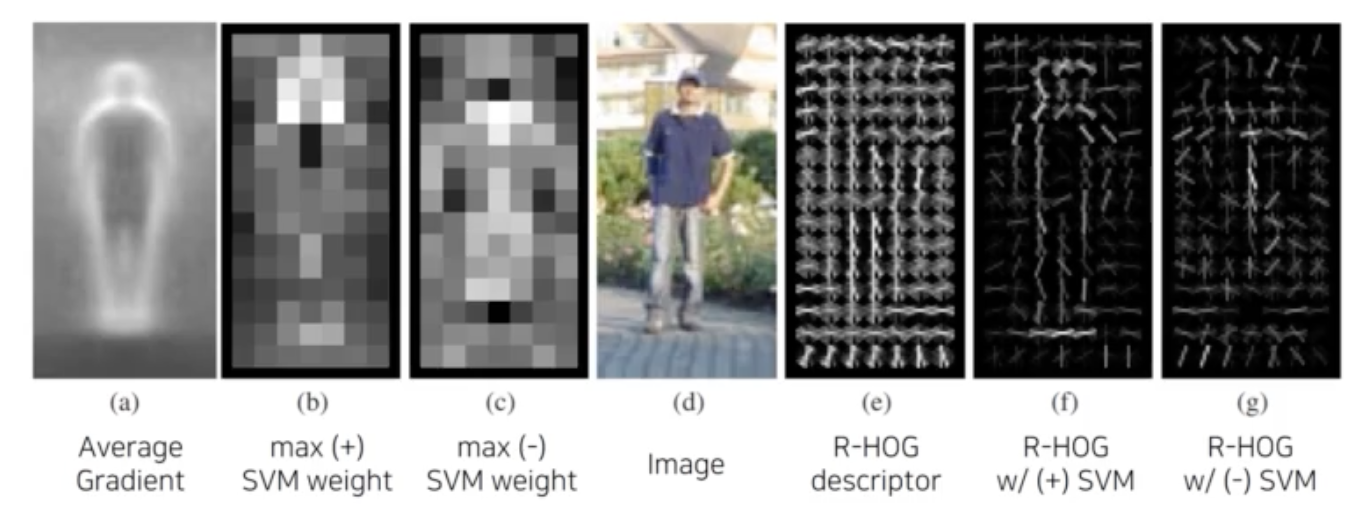
사람 영상의 경계선의 평균선을 내자 실루엣을 찾아낼 수 있었다. 영상의 경계선을 특징으로 모델링하면 사람 찾는데 도움이 되는구나, 라는 엔지니어링 기법이 유행했다. (사람의 직관에 의존한 알고리즘)
외곽을 뽑고, SVM을 통해 관심 물체인지 판별기를 학습했었다.
이를 통해 왼쪽의 세 사진같이 경계선들의 분포를 찾아낼 수 있었다.
f는 사람 형태 학습한 것, g는 사람이 아닌 것
feature를 정교하게 사람이 디자인 하고, 머신러닝 알고리즘이 간단한 선형 모델을 학습했다.
아래는 최근 까지도 사용한 기술
Selective Search
사람이나, 특정 물체 뿐만 아니라, 다양한 물체 후보군에 대해서 영역을 특정해서 제안해주는것
Box Proposal Algorithm 이라고 하기도 한다.

- Over-Segmentation: 영상을 비슷한 색끼리 잘게 구분
- 잘게 분할 된 영역들을 비슷한 영역들끼리 합쳐준다. (비슷하다? 색깔 혹은 gradient 특징 혹은 분포 등 기준 정해서)
- 반복해서 합쳐준다.
- 이를 통해 찾아낸 큰 segmentation(3번째 사진)을 포함하는 bounding box 를 추출해서 물체의 후보군으로 사용
첫번째 Deep learning 기반 Object Detection
object detection은 one stage, two stage 로 나뉜다.
https://ganghee-lee.tistory.com/34
1-Stage detector와 2-Stage detector란?
직선을 기준으로 위가 2-Stage Detector들이고 아래가 1-Stage Detector들이다. Regional Proposal과 Classification이 순차적으로 이루어진다. Regional Proposal 이란? 기존에는 이미지에서 object detection을..
ganghee-lee.tistory.com
1) Two Stage
R-CNN
기존 대비 압도적 성능
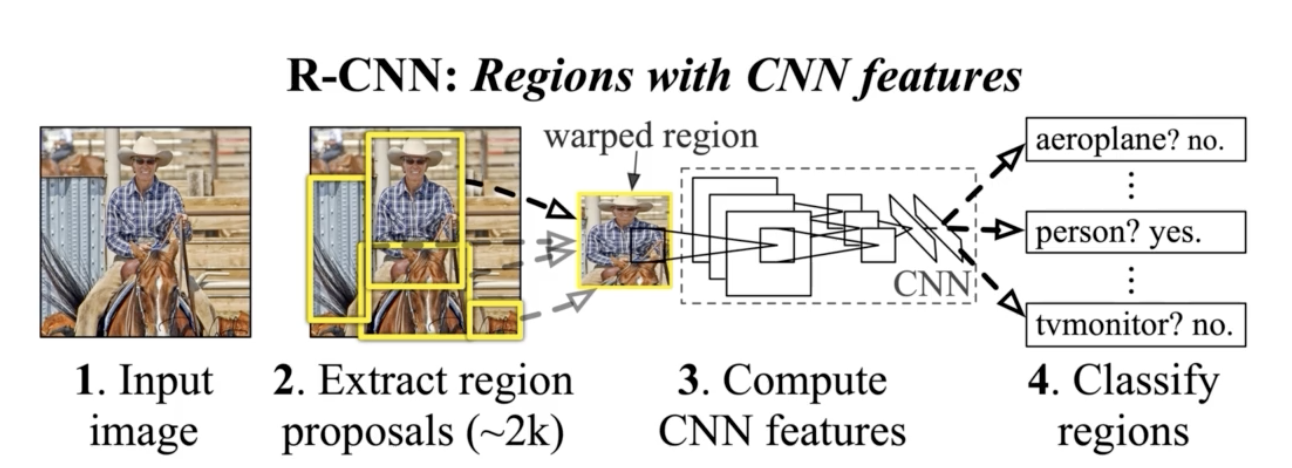
- Selective search 로 region proposal
- Image classification conv neural net으로 input size 를 warpping
- CNN 에 넣음
- Category classification: FC layer 에서 추출한 feature를 기반으로 SVM 학습해서 사용
각각 region proposal 마다 model에 넣어서 processing해야 해서 너무 느렸다.
region proposal 은 별도의 hand design (seletive search) 학습을 통한 성능 향상에 한계가 존재
Fast R CNN

Selective search 대체
Original image에서 conv layer를 통과시켜 feature map을 뽑는다. (C, W, H)
(Fully convolution 한 구조에서는 입력 크기에 상관없이 feature map 추출 가능 즉 wrapping 필요 X)
ROI(region of interest) pooling (한번 뽑아놓은 feature를 여러번 재활용)
ROI: region proposal 이 제시한 물체의 후보
Bounding box 가 주어지면 ROI 해당하는 feature 만 추출, 일정 사이즈로 resampling
즉 ROI pooling은 특정 사이즈를 가질 수 있도록 resize 한다.
정밀 위치 탐색을 위해 Bounding Box regression 수행

18배 속도 향상 그러나 여전히 region proposal 이기에 속도 한계
여전히 region proposal은 손으로 디자인한 알고리즘이기에 단점으로 존재 (data로 성능 높이기에 한계가 있다.)

ROI Pooling은 간단히 정리하면
feature map 과 selective search 를 동시에 진행한다.
원본 이미지에 대해 feature map 을 얻고, 동시에 원본 이미지에 selective search를 통해 region을 propose한다.
원본대비 region의 비율에 맞게 feature map 에서 해당 크기를 뽑아낸다.
즉 여기서는 800 X 800 $\rightarrow$ 8 X 8
8 X 8 $\leftarrow$ 500 X 700
$\rightarrow$ 5 X 7
그 이후, 추출한 RoI feature map을 2 X 2 크기로 만들어주기 위하여 비율에 맞게 grid 를 나눈다.
5 X 7
2 X 3, 2 X 4
3 X 3, 3 X 4
아마 이렇게 나뉘지 않을까?
그 후 grid 의 각 셀에 대하여 max pooling을 수행하여 고정된 크기의 feature map 을 얻는다!
2 X 2 !
이처럼 미리 지정한 크기의 sub-window에서 max pooling을 수행하다보니 region proposal의 크기가 서로 달라도 고정된 크기의 feature map을 얻을 수 있다.
Multi-task loss 관련 내용은 일단 생략한다.
Faster R- CNN
Region Proposal 이 neural net 으로 대체 (첫 End to End)

두영역의 합집합 분의 교집합을 통해 두영역이 잘 적합되는지 확인하는 기술
Region Proposal
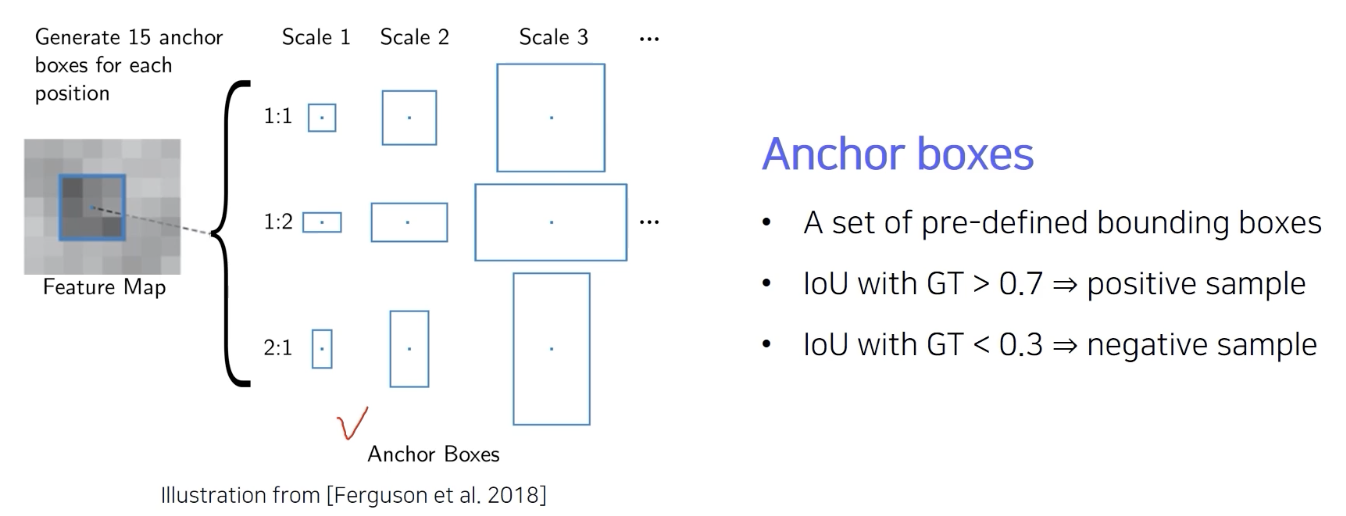
scale과 aspect ratio 의 다양화 3 X 3 = 9
미리 rough하게 각 위치에 발생할 것 같은 후보군 박스들을 정해놓은 것이 바로 anchor box
anchor box 중 positive , negative 구분 가능
GT 는 한개, GT 에 해당하는 것만 positive 로 구분해서 학습을 해야한다.
- IoU가 0.7이 넘으면 positive 하다고 판단
- IoU가 0.3 보다 낮으면 negative하다고 판단
학습 데이터의 bounding box 와 loss를 정하는 기준
Region Proposal network

Selective Search 와 같이 third party 의 알고리즘 대신에 region proposal network, RPN 을 제안하여 대체했다.
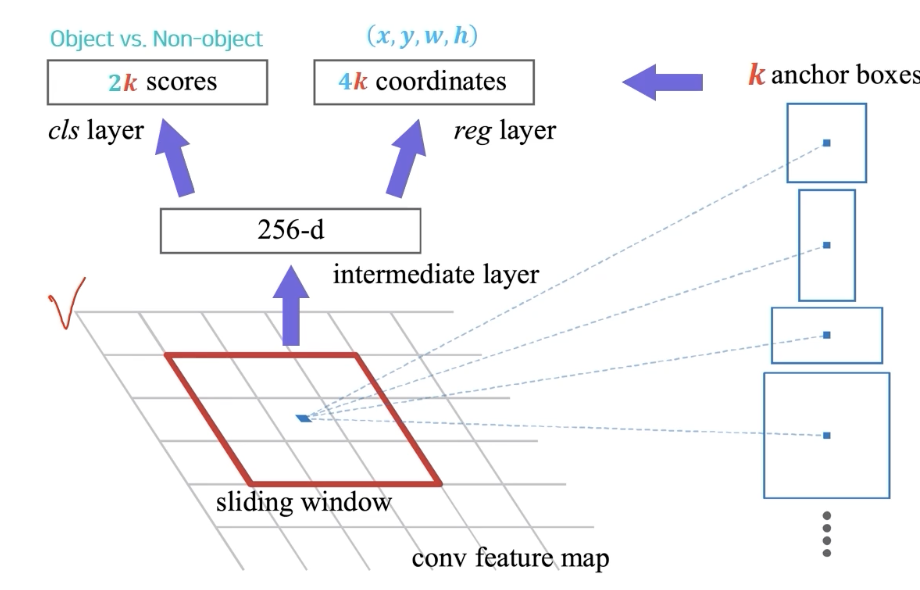
256 dimension의 feature vector에서 object인지 아닌지를 분석한 2 k 개(object, non-object)의 classification score와
k개의 bounding box의 정교한 위치를 regression하는 4k개(x,y,w,h)의 regression output이 출력.
anchor box 가 엄청 촘촘하게 사용한다면 regression이 필요 없겠지만, 이건 계산 속도가 너무 오래 걸린다. 이에 따라 적당한 양의 anchor box 만 적당히 만들고 그 후 regression을 통해 문제를 해결하겠다는 것.
학습 시
object 인지 아닌지 classification (cross entropy) loss, regression 용 regression loss $\rightarrow$ RPN
categorical classification 에 대한 classification loss $\rightarrow$ 전체 타겟 task를 위한 ROI별 categorical classification
end to end 로 학습이 된다.
RPN 에서 일정한 threshold 를 정하는 것이 어렵다. 엄청 많이 중복되고 겹쳐진 bounding box 가 나올 수 있다.

효과적으로 필터링과 screening 해주기 위한 방법: Non-Maximum Suppression (NMS)
그럴듯한 object bounding box 만 남겨두고 허수로 막 제안한 것들을 제거한다.

위 과정 반복

R-CNN CNN 부분도 pretrained 된 것, 마지막 classifeir 만 학습
Fast R CNN 하나의 feature로부터 여러개 물체를 탐지 할 수 있도록 만들면서 CNN부분을 학습 가능하도록 했다. 그러나 region proposal은 학습가능하지 않았다.
Faster R CNN RPN 제안 전체 프로세스가 end to end 로 학습
2) One(Single) Stage
정확도를 조금 낮추더라도 속도를 높혀서 real time 을 꾀함
Region proposal 을 기반으로한 ROI pooling을 사용하지 않고 바로 box regression과 classification을 수행하여 구조가 간단하고 빠르다.

Two stage는 sampling 된 위치만 선별적으로 진행
YOLO (You only look once)

Yolo는 직접 구현해볼 예정
Faster R CNN 과 YOLO 비교

Faster R CNN
이미지를 한장 집어넣고 Conv layer 를 쭉 통과시킨다.
그 후 마지막 feature map 을 뽑고 거기서 RPN 를 통과시켜서 물체 예상 위치에 bounding box 를 initial로 만든다. 여기서 classification을 수행하는데, 이건 여기에 물체가 있다 없다만 판단
거기서 뽑힌 bounding box 를 ROI pooling을 통해서 classification과 Bounding box regression을 진행한다.
YOLO
이미지를 집어넣고 CONV layer 로 feature map 뽑고 FC layer 에 vector 를 집어넣은 후 다시 tensor로 만든다.
SSD (Single shot multibox detector)
https://www.youtube.com/watch?v=ej1ISEoAK5g

(x,y)는 센터 좌표
w,h 는 사진 width height
Faster R CNN 은 실시간이 불가했다. 7 FPS with mAP 73.2%
Yolo와 SSD 비교
YOLO
45 FPS with mAP 63.4% 정확도를 너무 희생했다.
SSD
59 FPS with mAP 74.3% on VOC2007 test
이후 one stage detector는 모두 SSD 기반 (YOLO는 자기만의 길을 간다.)
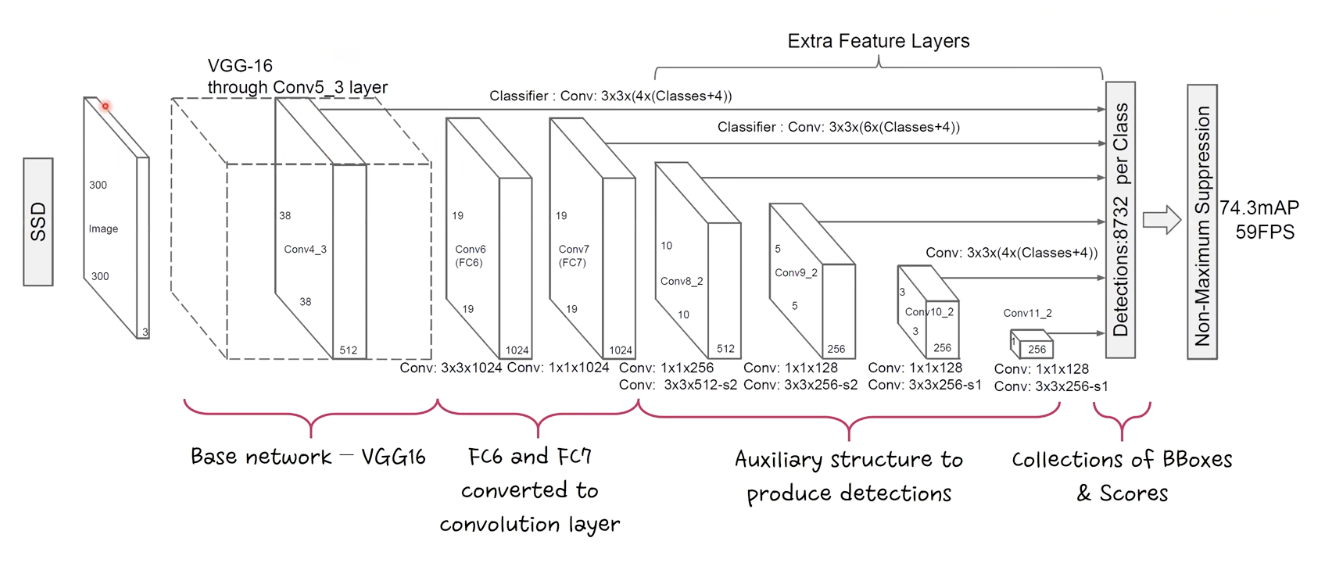
네트워크 구조
VGG16 을 base network 로 사용
[CNN 알고리즘들] VGGNet의 구조 (VGG16)
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com
참고 VGG 의 구조
기존 VGG16 의 FC 6,7 자리를 CONV layer 로 대체 뒤에 추가로 conv layer 몇개 쌓음
1 X 1 으로 크기 줄이고, 3 X 3 conv 적용 반복
300 X 300 기준 bounding box 를 8732 개를 뽑는다. VS YOLO 는 98개
특징은 중간 중간에 feature map 을 만들어가면서 bounding box 를 계속 뽑아낸다.
$\rightarrow$ multi sacle feature map 사용
$\rightarrow$ 앞쪽에서는 공간 위치 정보, 뒤로 갈 수록 abstract feature level이 더 높다. 모두 활용
VS YOLO는 single scale feature map 만 사용을 했다. 즉, 공간 위치 정보 모두 담으려는 시도는 아니다.
SSD는 p(channel) X m X n 의 fature layer 에 대해 detection을 수행할 때 p(channel) X 3 X 3 convolution 을 수행한다.
이를 통해 category의 점수를 산출(classification)하고, bbox regression 을 한다.
VS YOLO는 점수와 bbox 의 좌표를 위해 Fully connected layer 를 가지고 있다.
Bounding Box 몇개를 어떻게 뽑을까?

Bounding Box 하나를 뽑을 때 (x,y,w,h) 4개의 정보와, c개의 classification 정보가 필요
이에따라 c+4 개 만큼의 크기가 필요
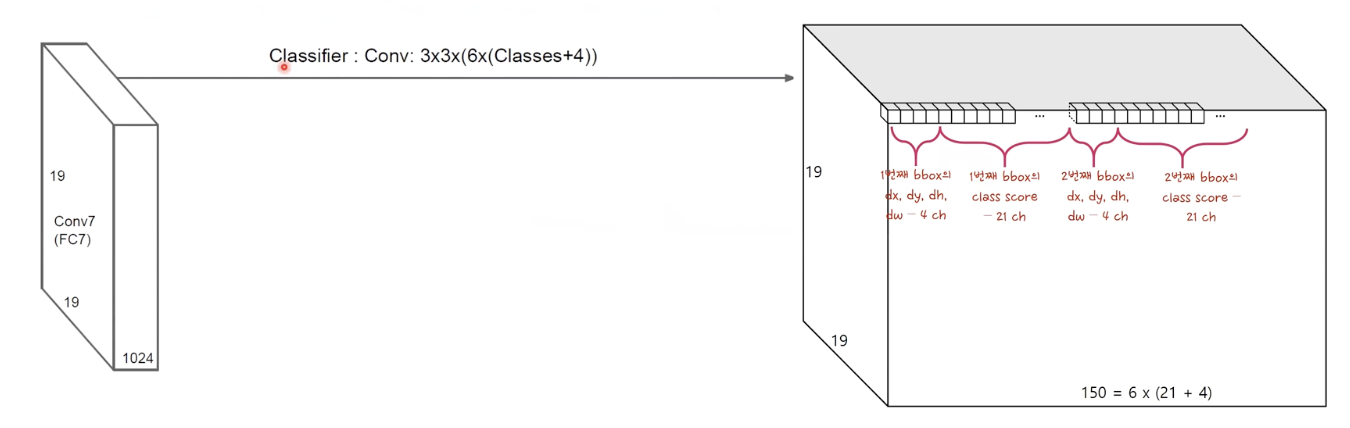
하나의 location k의 bounding box를 뽑는다. (4개 아님 6개 여기서는 6개)
각 bounding box 마다 (c+4)개 크기가 필요

이에 따라 output channel은 6 X (c+4) 개수
pascal VOC 는 class 가 20개 + bounding box 가 background 인 경우 1
(21 + 4)X 6 = 150
가로 세로는 19 X 19
IoU 는 위에 작성 되어있다.
- 간단하게 GT 와 가장 많이 겹치는 애 하나를 뽑고,
- 많이 곂치는 애와 0.5 이상 겹치는 애들은 GT 를 맞춰야 할 의무가 있는 후보군에 다 포함시킨다.
Loss function

$N$: 바로 위에서 언급한 matching 된 bbox 의 개수
$conf$: Cross Entropy loss
$loc$: Localizationg loss (bbox regression)

bbox 의 비율은 확 커졌다가 작아졌다가 할 수 있다. 그로 인해 bbox 는 log 스케일을 사용한다.
모든 detection algorithm에서 공통적으로 사용
vs YOLO 는 direct하게 위치 추정 (다만 YOLO2 부터는 개선)
몇번째 feature map 에서 bbox를 뽑아내냐에 따라 원본 이미지 기준 볼 수 있는 영역의 크기가 다르다. (feature map이 얼마나 압축되었냐에 따라서)

큰 물체는 뒤쪽에 있는 상대적으로 뒤쪽에서 detect 하고 작은 물체는 앞에서 detect한다.
(GT와 IoU 가 0.5 넘는애를 찾다보면 당연지사)
$\rightarrow$ resoultion 큰 feature map에서는 작은 object, 작은 feature map에서는 큰 object
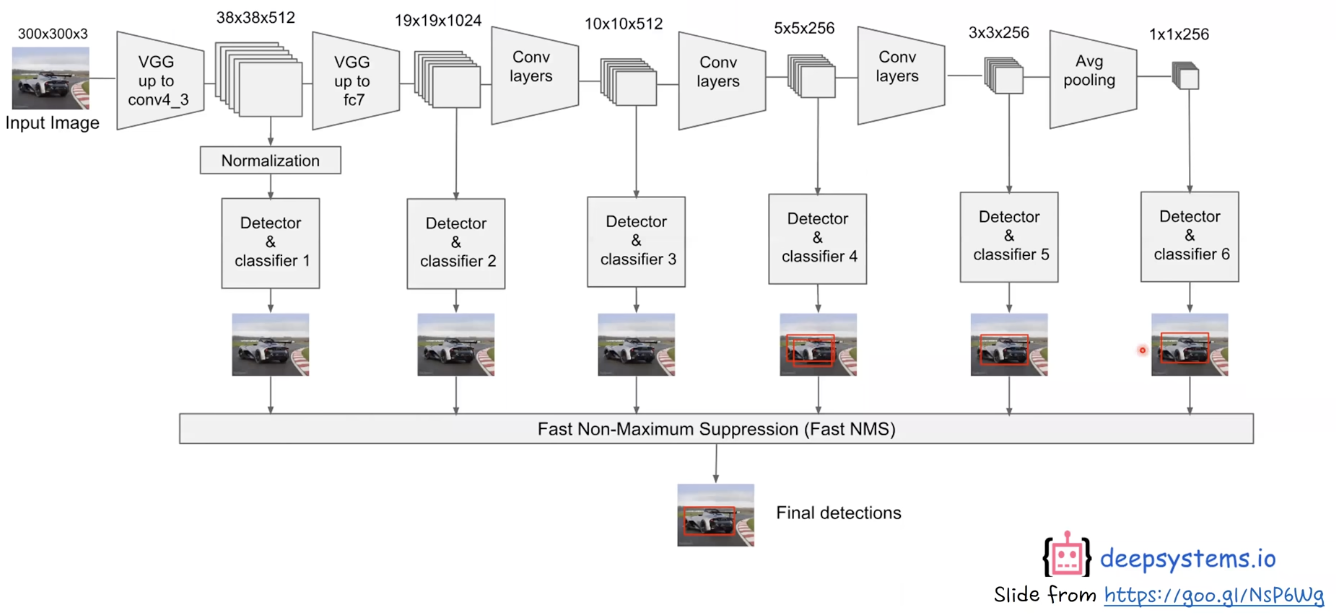
또한 한 개의 물체를 여러개의 bounding box 가 맞추려고 노력하기 때문에 inference time에 정확도가 더 높아진다.
default 로 bbox를 만드는 방법
(scale 식)
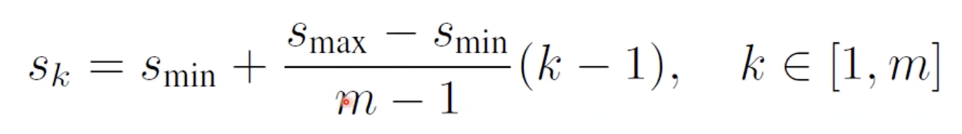
$s_min$: 0.2 $s_max$: 0.9
m: 총 몇개의 feature map 에서 bbox를 뽑아낼 것인가? (이 논문에서는 6개)
k: m개의 feature map 중 몇번째 feature map 인가?
실제 실험에서는 $s_k$: 0.1, 0.2, 0.375, 0.55, 0.725, 0.9 로 한다고 되어있다.
means 30, 60, 112.5, 165, 217.5, 270 pixels (input img 300 X 300)
scale 을 정하고 나면, aspect ratio 는 다음과 같이 정해진다.

다만, bbox를 6개 뽑으면 ratio 는 5개만 있으므로 하단의 공식(조화평균)을 통해 ratio 를 하나더 만들어준다.
$ s^{'}_{k} = \sqrt{s_k s_{k+1}} $
Hard Negative Mining
bbox 를 많이 뽑아도(예를 들어 8000개) 그 중 사실 물체는 많아야 10개인 경우가 많다.
각 3개의 bbox 가 10개의 물체를 맞춘다고 하면 총 30개의 bbox가 GT와 매치가 되고 나머지는 다 background가서 쳐졌다는 뜻인데,
결국 background 에 대한 데이터는 엄청 많고 나머지 클래스에 대한 데이터가 작은 클래스 imbalance 문제가 발생한다.
이 문제를 어떻게 해결하는가?
그냥 classification 문제를 풀 때 써보는 방법 중 하나인 Hard Negative Mining
Highest Confiedence loss 를 갖는 애들을 순서대로 뽑아서 쓰겠다는 뜻
background 가 굉장히 많은 bbox 에서 발생하는 loss 를 모두 쓰는게 아니라 loss 가 큰 순서대로 뽑아서 쓴다.
background인데 background가 아니라고 판단한 애들. 잘 못 맞춘 애들만 순서대로 sorting 해서 positive example 의 딱 3배만 사용한다.
즉 positive example 과, background 중에서는 잘 못맞춘 애들을 고루 섞어줌(1:3)으로써 두 문제 모두 해결
단, 작은 물체는 잘 못찾는다. (초기 단계 featuremap 이 충분히 추상화되지가 않아서)
여기서는 data augmentation으로 해당 문제를 해결해보고자 함

그냥 크기를 줄이고, 배경은 이미지의 평균 값으로 채워버리고 실험 진행
성능이 상당히 향상 되었다.
Inference speed, mAP

방금 SSD 에서 언급된 class imbalance 를 좀더 심도 있게 살펴보자.
Focal Loss

single stage 방법들은 ROI pooling이 없다보니 모든 영역에서 loss가 계산되고 일정 gradient 가 발생한다.
일반적인 영상에서는 background 영역이 더 넓고, 실제 물체는 아주 작은 영역만 차지한다. 심지어 detection 문제에서는 물체가 적당한 크기의 bbox 하나로만 취급이 된다.
positive sample 은 적은 반면, negative sample은 정보도 없으면서 엄청난 영역과 개수로 class imbalance 문제가 있다.
이를 위해 등장한 Focal loss

cross entropy 의 확장
gamma parameter에 따라서 function 의 shape 이 결정된다.
파란 색 선이 cross entropy
:true class에 대한 score 가 높게 나와서 정답을 잘 맞추게 되는 영역을 보면 낮은 loss값을 반환하고 맞추지 못하면 큰 loss 값을 반환하는 표준적인 loss
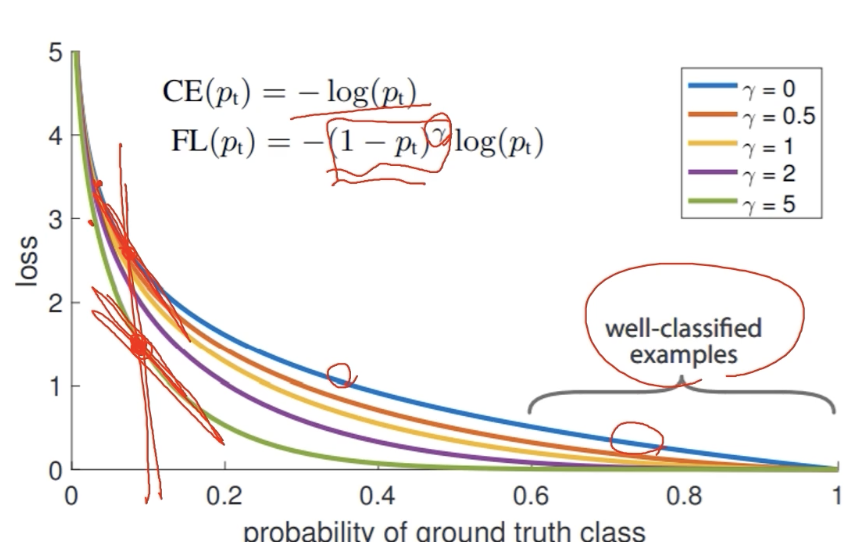
Focal loss는 앞에 확률 term을 붙여줘서, 잘 맞춘 애들은 더 loss를 낮게 만들고, 못 맞추면 더 sharp 한 loss를 준다.
다만 gamma 에 따라서 휘는 각도가 급격하게 변하는데, 막상 오답일 때는 gamma가 큰 경우에 더 작은 loss 를 갖는다.
왜일까? network를 학습할 때 graident를 쓰므로 오히려 gradient는 크다. 즉, gamma 가 클 수록 gradient는 더 sharp 하게 변한다. 반면에 정답을 맞추면 gradient가 거의 0에 수렴한다. 즉, 정답을 가까울 수록 gradient가 거의 무시된다.
즉 어렵고 잘못 판별되는 예제들에 대해서는 더 큰 weight 주고, 쉬운 task는 조금 준다.
FPN (feature pyramid Network):
Unet 과 유사한 구조
low level의 특징 layer 들과 high level의 특징을 둘다 잘 활용하면서도 각 scale별로 물체를 잘 찾기위한 multi scale 구조를 가지기 위하여 다음과 같이 설계되었다.

중간 중간 feature 를 다음으로 넘겨주고 더해서 fusion을 한다. (Unet과 달리 concat이 아니고 더하기)
class head 와 box head 가 따로 구성이 되어서, classification 과 box regression을 dense 하게 각 위치마다 수행한다.
이런 구조를 합쳐서 RetinaNet이라한다.
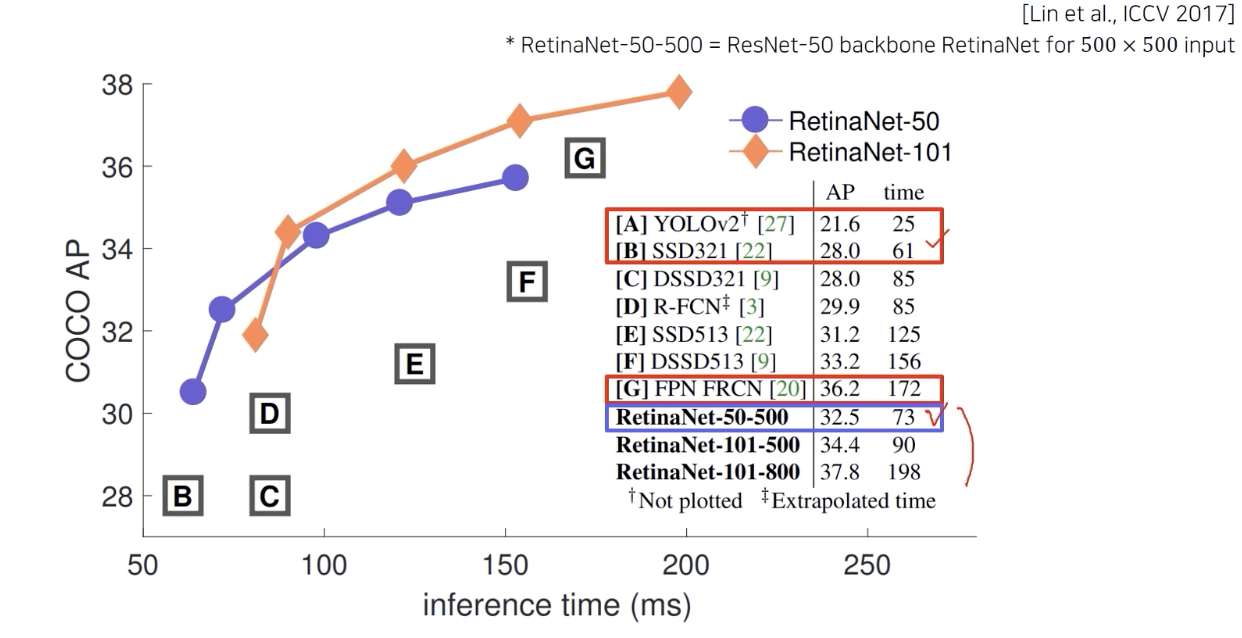
SSD 와 비슷한 속도, 굉장히 높은 성능
속도를 느리게 하면 성능이 더 높아진다는 걸 보여주었다.
Detection with Transformer
ViT(Vision Transformer) by Google
...
DETR(DEtection TRansformer) by Facebook
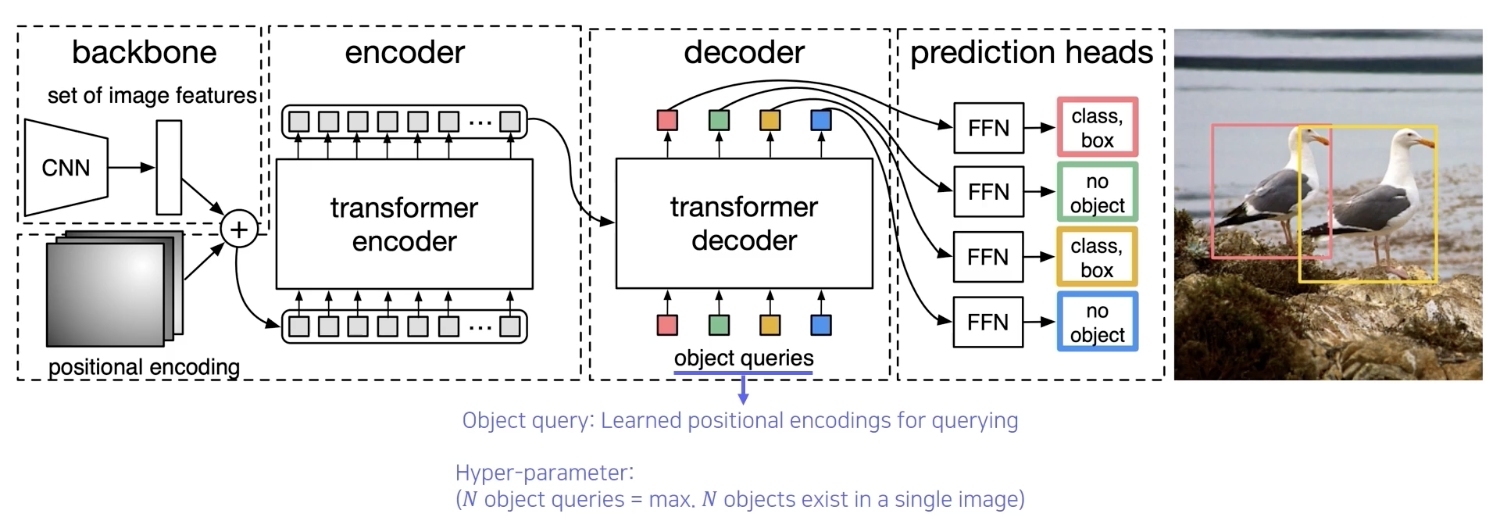
CNN 의 각 feature와, 각 위치의 multi dimension으로 표현한 enconding 을 쌍으로 해서 입력 token을 만들어 준다.
그후 transformer enconding 을 거치고 그후 추출된 특징들을 decoder에 넣어준다.
object query 를 활용해서 transformer 에게 질의를 한다. 방금 decoder 에 들어간 object, 즉 이 위치의 object가 뭐냐?
query는 학습된 position encoding.
빨간색을 넣어준 위치에 어떤 물체가 있는지에 대한 정보가 parsing 되는 형태
그 위치에 물체가 있는지, 있다면은 box 는 어떻게 그려야 하는지에 대해서 출력
영상 전체를 질의로 하나하나 넣어준다. 그 응답을 detection 구조로 사용.
no object가 아닌 경우만 표기를 한다.
Object Detection 의 또다른 trend
detection bbox 를 regression하지말고 다른 형태의 data 구조로 탐지해보자.

박스 표현 대신에 물체의 중심점을 대신 찾거나, 왼쪽 위와 아래의 양끝 점을 찾는 것으로 regression을 피하고 좀더 효율적으로 계산한다는 등의 수고가 있다.
'AI > CV' 카테고리의 다른 글
| Conditional generative model (0) | 2022.03.16 |
|---|---|
| Instance segmentation, Panoptic segmentation (0) | 2022.03.14 |
| FC layer 를 1X1 Convolution 으로 바꾸기 (0) | 2022.03.12 |
| AutoGrad (0) | 2022.03.11 |
| CNN Visualization (0) | 2022.03.11 |



