
꺼내먹는지식 준
semantic segmentation, Detection 본문
Semantic Segmentation (Dense Classification, per pixel classification)

각 이미지의 pixel마다 분류를 하는 과업 (모든 픽셀이 어떤 label인지 파악)

최대 활용 분야: 자율 주행 (게임에서 의미를 파악하는 데 사용할 수 있지 않을까?)
Fully Convolutional Network (here after, FCN)


왼쪽의 dense layer 를 없애고자 하는 것 .
다만, 해당 과정(왼쪽, 오른쪽) 각각의 parameter 의 개수는 정확히 일치한다.

left: 4 $\times$ 4 $\times$ 16 $\times$ 10 = 2,560
right: 4 $\times$ 4 $\times$ 16 $\times$ 10 = 2,560
(이해가 안가시는 분들은 다음의 글 참고)
한줄로 펴는가, 혹은 옆으로 돌려서 Convolution을 가지고 FCL가 하던 것과 동일한 역할을 하는 것.
이러한 행위를 Convolutionalization 이라 한다.
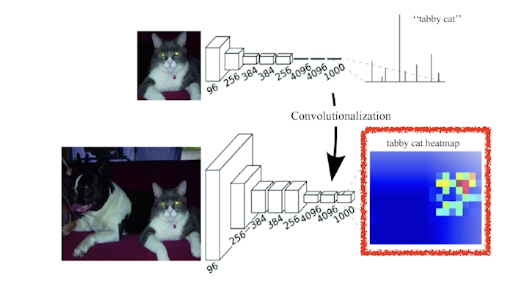
왜 할까?
1) Input의 spatial dimension에 independent 하다.
$\rightarrow$ input 이 커지게 되면 비례해서 뒷단의 spatial dimension 이 커진다.
Convolution은 shared parameter로 인해 input image가 커지던 말던 동일한 filter가 동일하게 찍어 나오기 때문에 찍어 나오는 result의 spatial dimension만 같이 커지지 여전히 동작은 가능하다.
2) 그리고 해당 동작이 heat map 과 같은 효과가 있다.
다음과 같이 해당 이미지에서 고양이의 위치를 찍어낼 수 있다.
주의해야 할 점은 이미지의 spatial dimension이 많이 줄어들었다. (ex. 100 $\times$ 100 $\rightarrow$ 10 $\times$ 10)
그럼에도 단순히 분류만 하던 네트워크가 히트맵 혹은 Semantic Segmentation할 가능성이 발생한 것이다.
FCN 은 어떠한 spatial dimension 에서도 돌아갈 수는 있지만 output 의 spatial dimension이 줄어 들기는 한다(coarse output).
다음과 같은 output 을 원래의 dense pixels로 다시 늘릴 수 있는 방법이 필요하다.
Deconvloution (conv transpose)
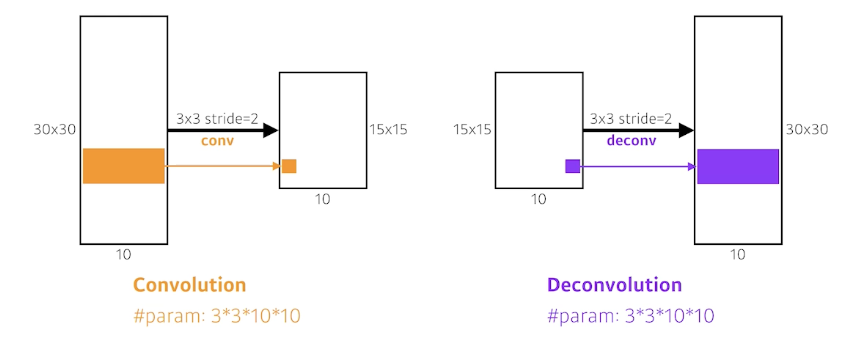
Convolution의 역 연산으로 크기를 다시 키워주는 격(Upsampling)이다.
다만 실제로 Convolution의 역 연산이라는 것은 존재하지 않는다.
3 $\times$ 3 의 정보를 합쳐서(aggregate) 하나의 pixel로 만들기에 복원은 불가능 하다.
엄밀히 말하면, 역은 아니지만 역으로 이해하면 모델 구조를 짤 때 파라미터 개수라던지 이런 부분에서 활용하기에 좋다.

다음의 방법들이 예시가 될 수 있다.
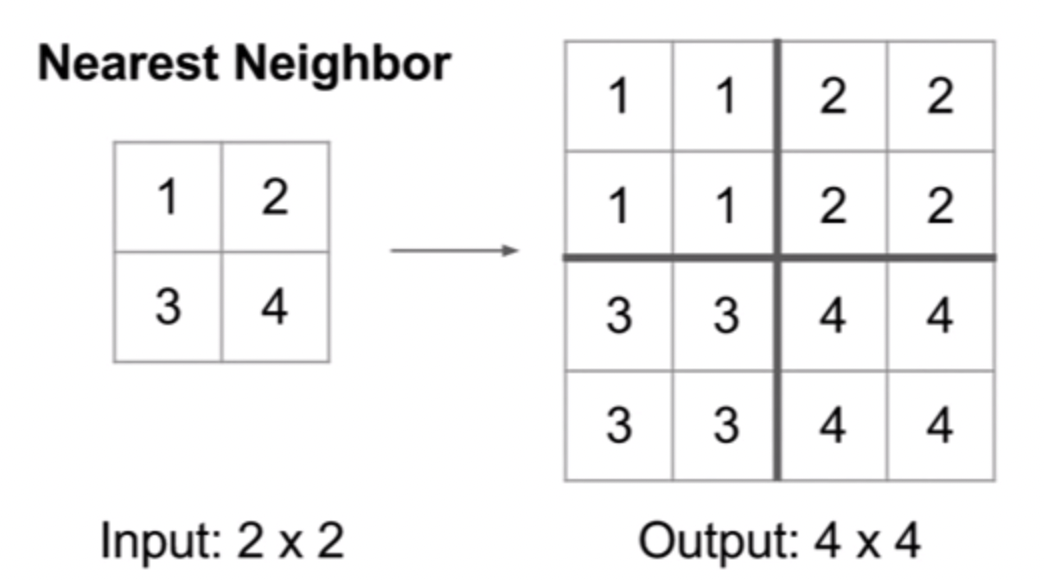


결과

Detection
가장 간단한 방법 R-CNN

이미지 안에서 2000개 가량의 region을 뽑아낸다. (Selective Search)
그 후 region의 크기를 맞춰준다.
Feature는 AlexNet으로 뽑는다.
분류를 한다. (Linear Support Vector Machine)
굉장히 Brute Force형태로 오래걸린다.

대략 어느 위치에 어느 물체가 있는지 나오지만,
다음과 같이 정확하지 않다.
이미지 안에서 2000개의 bounding box를 뽑으면, 이 patch가 모두 CNN을 다 통과시켜야 했다.
즉 하나의 이미지 당 처리 시간이 1분이나 걸렸다.
SPPNet

SPPNet은 이미지 하나당 CNN을 하나만 돌리고자 하였다.
이미지 안에서 bounding box를 뽑고, 이미지 전체에 대해서 Convolutional featuremap 을 만든 후.
뽑힌 bounding box의 위치에 해당하는 convolutional feature map의 tensor 만 가져오자.
Covolutional layer를 한번 돌지만, 해당하는 위치의 sub tensor를 뜯어오는 건만 region별로 하기 때문에 RCNN에 비하면 많이 빨라졌다.
추가적으로 뜯어온 feature map 을 하나의 fixed vector로 잘 바꿔주었다. (궁금하면 논문 참고)
그럼에도 bounding box 만큼 tensor 를 뜯어와서 벡터 하나 만들고 분류를 해줘야 해서 오래 걸렸다.
Fast R-CNN

Input image $\rightarrow$ Selective Search를 통해 bounding box 뽑는다.
$\rightarrow$ Convolutional featuremap을 한번 얻는다. (SPPNet과 동일)
$\rightarrow$ 각각의 region에 대해서 고정된 길이의 feature을 뽑아낸다.
$\rightarrow$ neural net을 통해 내가 얻은 bounding box 를 어떻게 움직이면 좋을지, label을 찾아낸다.
SPPNet과 거의 동일한데, 뒷 단에 neural net이 붙었다는 점이 다르다.
Faster R-CNN

bounding box 를 뽑아내는 region proposal도 학습을 하자! 라는 아이디어 제안
지금은 selective search로 지금 찾고자 하는 detection과 잘 맞지 않는다.
candidate를 뽑는 방식을 network로 학습하자는 것. (Region Proposal Network)
Region Proposal Network (here after, RPN)

이미지에서 특정 영역이 bounding box 로서의 의미가 있을지(즉, 물체가 안에 있을지)를 찾아주는 것
Anchor box: detection boxed with predefined size
이미지 안에 대충 어떤 크기의 물체들이 있을 것 같다를 미리 아는 것
일종의 template을 만들어 놓고 얼마나 바뀔지에대한 offset을 찾고 궁극적으로는 template을 고정해 놓는 것이다.

해당 영역의 이미지가 과연 물체가 들어있을지를 Kernel이 즉 Fully Convolutional layer가 들고 있게 된다.
predefined region size: 9개 (위 사진 참고)
각각의 region size 마다 bounding box 를 얼마나 키우고 줄일지에 대한 4개의 parameter
박스가 쓸모 있는지 없는지 결정짓는 파라미터 2개
총 54개의 channel

YOLO v1

엄청난 속도
baseline: 45 fps
smaller version: 155 fps
빠른 이유 region proposal network를 통해 무언가 구한것을 region에 해당하는 convolutinal featuremap의 subtensor를 가지고 분류를 하는 것이 아니라 이미지 한장에서 바로 ouput 을 구할 수 있다.
$\rightarrow$ 즉, 동시에 multiple bounding box를 예측하고, 분류 확률을 예측할 수 있다.
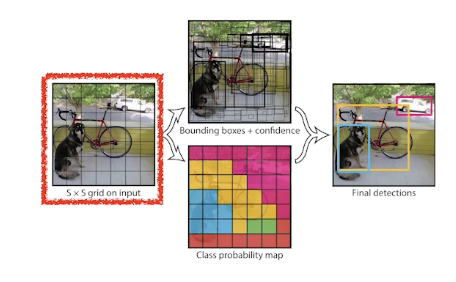
동작 방식
이미지가 들어오면 S $\times$ S 그리드 로 나눈다.
이미지 안에서 찾는 물체의 중앙이 해당 그리드 안에 들어가면 해당 그리드가 해당 물체의 bounding box 와 물체를 같이 예측해주어야 한다.
각각의 cell은 B개의 bounding box 를 예측한다. (B = 5)
찾은 box 가 쓸모있는지 확인
동시에 각각의 그리드에 속하는 중점의 object가 어떤 클래스인지 예측
기존에는 Bounding box 를 찾고, 찾은 것을 network에 넣어 돌려 클래스를 찾았다면
YOLO는 그 두개가 동시에 돌아간다.
그 두개의 정보를 취합하면 box와 box의 클래스를 알 수 있다.
이를 tensor로 표현하면 grid S $\times$ S $\times$ (B *5+C)
S $\times$ S: 그리드의 셀 개수
B * 5: 바운딩 박스의 offset (x,y,width,height)그리고 confidence
C: number of classes
$\rightarrow$ S $\times$ S $\times$ (B *5+C)
각각의 채널에 맞는 정보가 들어가도록 Neural Net이 학습

'AI > CV' 카테고리의 다른 글
| CNN Visualization (0) | 2022.03.11 |
|---|---|
| Semantic segmentation (0) | 2022.03.10 |
| Convolution network model 소개 (ILSVRC 모델) (0) | 2022.02.08 |
| CNN 간단 정리 2 (0) | 2022.02.08 |
| CNN 간단 정리 (0) | 2022.01.21 |



