
꺼내먹는지식 준
1 stage Detectors 본문
Yolo Familty, SSD, RetinaNet
2 Stage model
1) Localization (후보 영역 찾기)
2) Classification (후보 영역에 대한 분류)
$\rightarrow$ 속도가 매우 느려서, real time 으로 활용하기 위한 방법론 one stage


- feature map으로부터 바로 객체의 종류와 위치를 예측함으로써 RPN 과정을 생략
(localization, classification 동시 진행)
- 전체 이미지에 대해 특징 추출, 객체 검출 $\rightarrow$ 간단하고 쉬운 디자인
- 속도가 매우 빠름
- 영역을 추출하지 않고 전체 이미지를 보기 때문에 객체에 대한 맥락적 이해가 높음 (background error가 낮음)

YOLO

YOLO v1
network
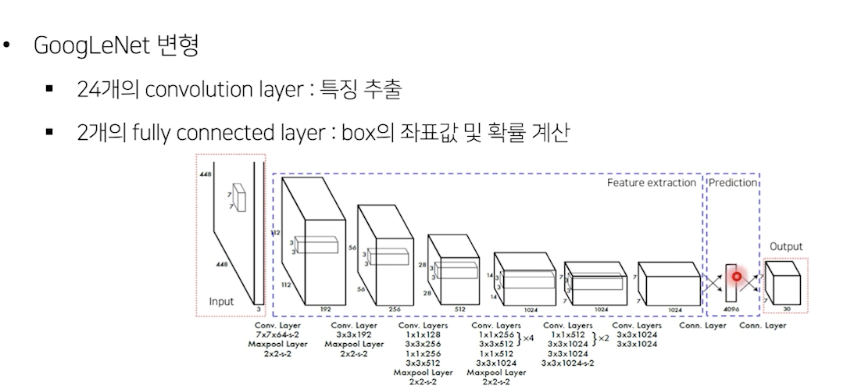
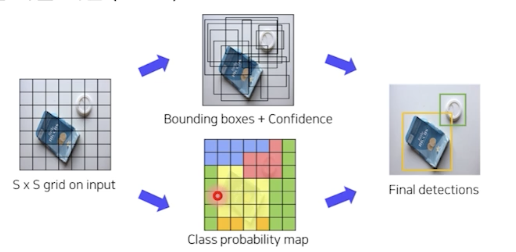
- 입력 이미지 S X S 그리드 영역으로 나누기 (S=7 in this paper)
- 각 그리드 영역마다 B개의 Bbox 와 confidence score 계산 (B = 2 한 그리드에 박스 2개 예측)

7 X 7 X 2 = 98 개
각 그리드 영역 마다 C개의 class에 대한 해당 클래스일 확률 계산 (C = 20)


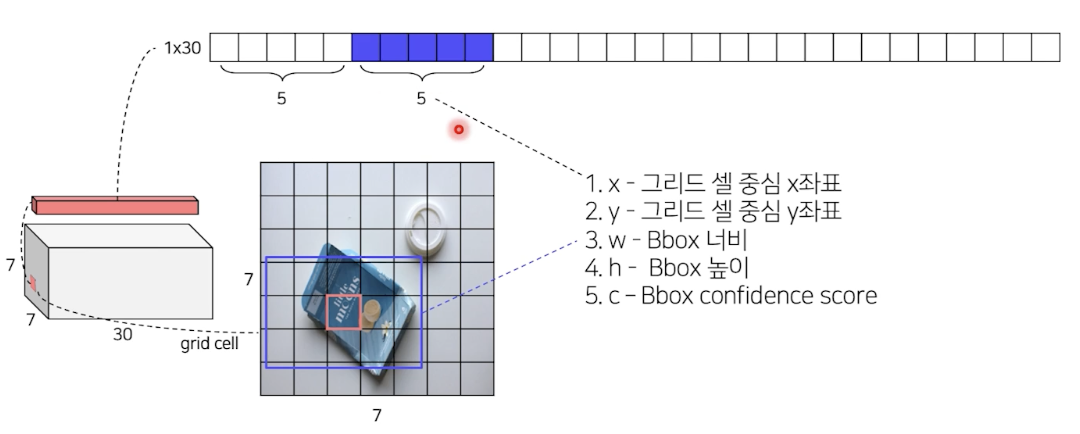
- output size: 7 X 7 X 30
- 하나의 그리드가 7 X 7 의 영역의 한 부분을 담당
- (Channel)feature 30개
output size
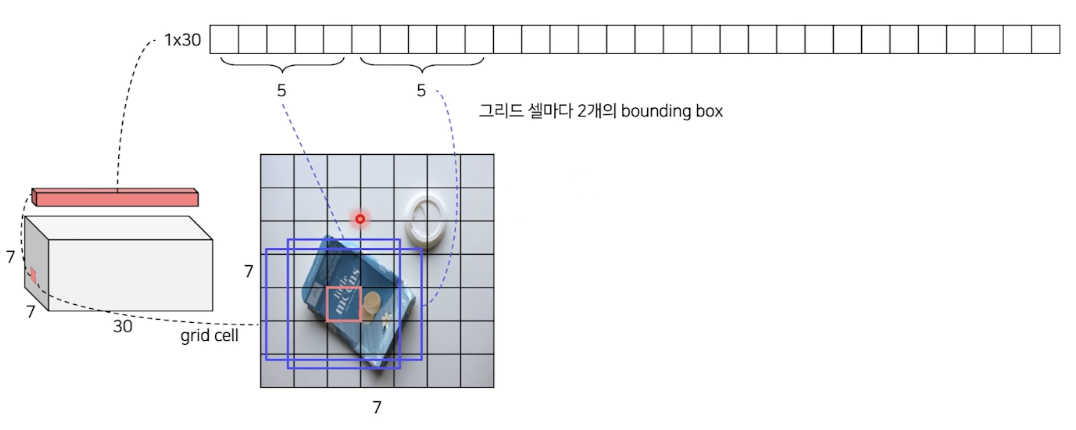

- 그리드 셀마다 다음과 같이 2개의 bbox 포함
- PascalVoc 20개의 class
Inference

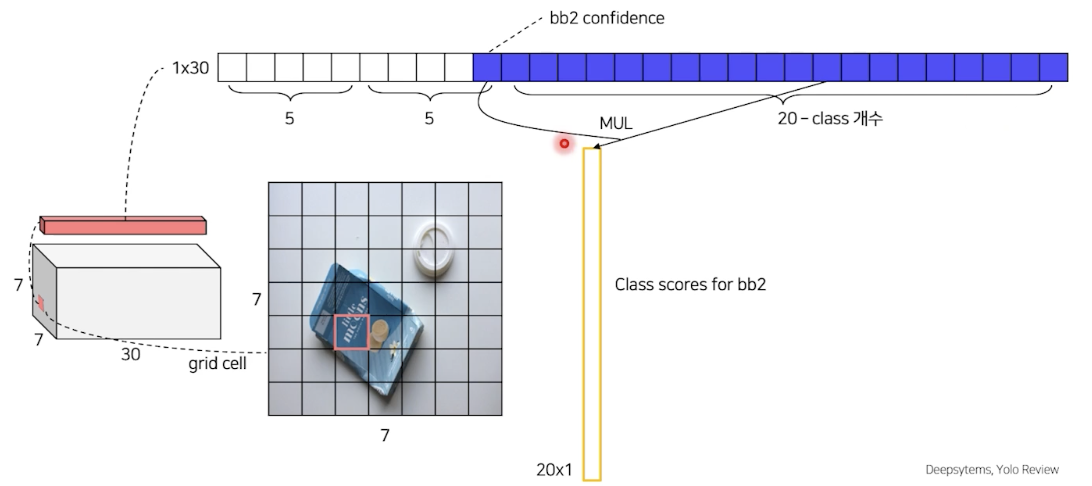
bbox1 confidence 확률과 각 class 에 대한 확률의 곱을 통해 bbox1에 대한 class score를 얻을 수 있다.
bbox2도 마찬가지
$\rightarrow$ 이 것을 각각의 grid cell마다 각각의 bbox 수행

총 98개 bboxes

각각의 bboxes 의 class score을 확인하고, 정한 threshold 보다 낮은 경우 모두 정보 제거
threshold 크기에 따라 내림차순 정렬
NMS fusion 연산을 통해 최종 정리
$\rightarrow$ 그 후에도 최종적으로 남아있는 bbox 들을 그려주면 inference 완료
(상단의 예시의 경우 bb3, bb1 이 종이박스 score로 남아있으니 bbox를 그려주면 된다.)

Localization Loss
$S^2$ 각 그리드 셀에, 각 $B$박스 별로 ($1_{ij}^{obj}$: object가 있을 때) 중심점의 위치 계산
즉, i번째 그리드 셀에서 j번째 박스에 오브젝트가 있을 때 중심점 위치에 대한 regression loss
+
각 그리드셀에, 각 박스별로 object가 있을 때 width와 height에 대한 regression loss
Confidence Loss
각 그리드 셀에, 각 박스별로 오브젝트가 있을 때, confidence loss 를 한번 계산 + obj 가 없을 때도 confidence loss를 한번 계산
classification Loss
각 그리드 셀에 오브젝트가 있을 때, 해당 클래스에 대한 확률의 MSE
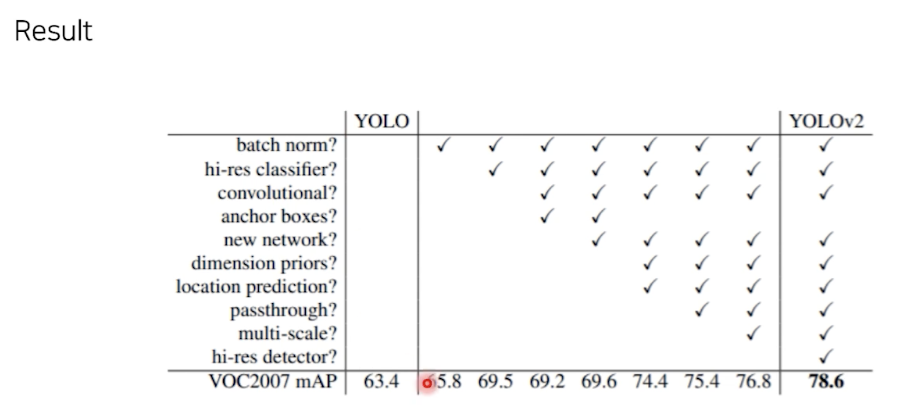
성능 (속도)

빠른 속도, 비교적 준수한 성능 (background erro는 특히 낮다.) Yolo로 background 솎아내고, Fast R CNN을 썼을 때 성능의 향상 (Ensemble)

그리드 셀 별로 어떻게 bbox 의 크기를 사전 지정(anchor box 없이)하는지에 대한 탐구 필
SSD
워낙 해당 블로그에 여러번 글을 작성했기에 링크만 단다.

https://itforfun.tistory.com/99
Object Detection 개괄 from selective search to SSD
해당 글은 Object Detection에 관련된 총 정리 글이다. 추후 Selective Search, Faster R CNN, Mask R CNN, Single Shot Multi-box Detector, Yolo 정도는 개별글을 올릴 예정이다. SSD 의 리뷰는 해당 글에 그냥..
itforfun.tistory.com
간단하게 Yolo 와의 차이점만 언급
- Yolo 는 fully conneceted 를 사용했기에 속도가 느렸으나, SSD 는 fully conneceted layer가 사라졌다.
- SSD: 300 X 300 | Yolo: 448 X 448
- SSD: feature map 여러번 뽑음, Yolo 는 마지막 feature map만 사용
SSD 내용은 꼭 위 블로그 글을 읽고오자.
SSD feature maps




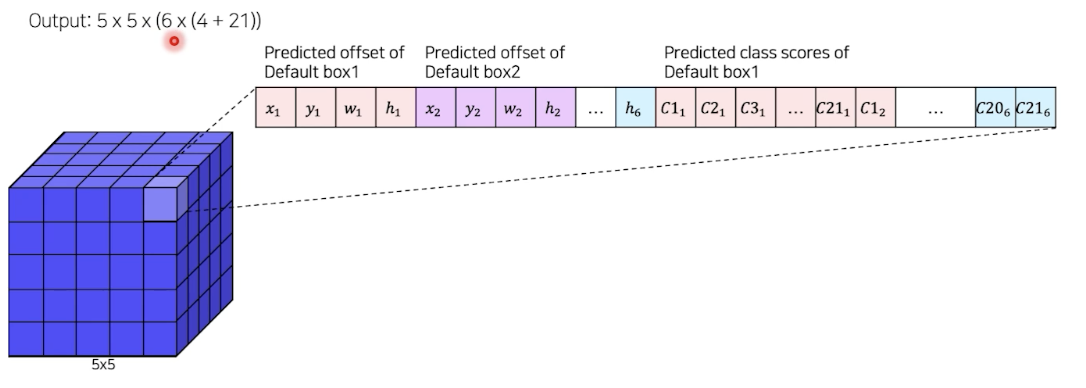
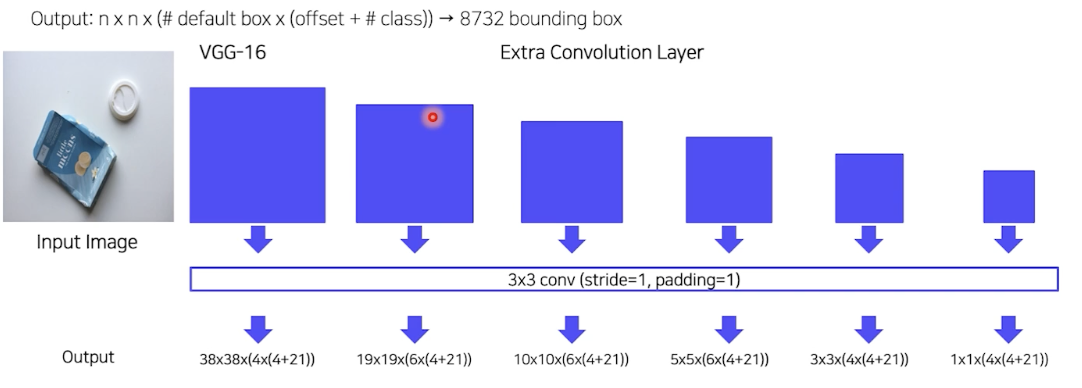
8732 개의 Bboxes

- Hard Negative Mining
- Non Maximum Suprresion

Loss function
classification loss + localization loss
localization loss
smooth error
anchor box 에서 GT box 사이의 delta 학습
classification loss
softmax

더 빠르고, 비교적 성능도 좋은 모델
YOLO followup
Yolov2




작은 low level의 정보를 함축한, 즉 fine-grained feature를 최종 layer 에 추가


성능


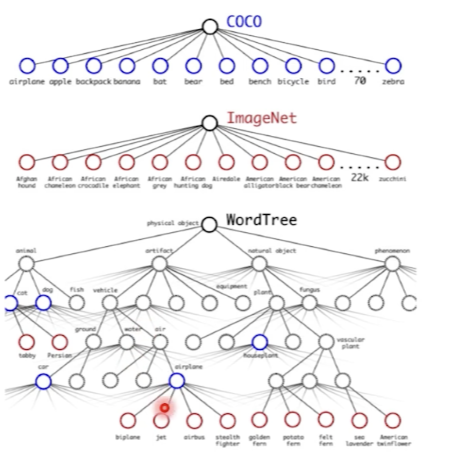

즉, coco data로는 거의 detection task 만 수행, ImageNet 으로는 classification 수행
이후 보지 못했던 데이터 set 에 대해서도 어느정도 object detection 수행이 가능했다는 흥미로운 점
YOLO v3
backbone 개선

Multi-Scale Feature maps

SSD 처럼 한게 아니고, FPN 사용
RetinaNet
one stage detector의 고질적 문제 해결
RPN 가 없기에 이미지에서 후보 영역을 뽑는게 아니라, 이미지를 grid로 나눠서, 각 grid 별로 Bbox를 무조건 예측하도록 하여 training을 수행하였다. 이로 인해 2 stage 에 비해 background를 포함한 경우가 많아서 class imbalance문제가 심각했다.

Focal Loss

- 기존의 cross entropy 동일하게 사용
- 단 쉬운 예제는 가중치를 적게, 어려운 예제에는 큰 가중치를 두어 어려운 예제에 집중
r value 가 커질 수록, 어려운 케이스에 대해 gradient 를 더 강하게 주는 것을 볼 수 있다.
$\rightarrow$ Object Detection 뿐만 아니라, class imbalance 가 존재하는 모든 task 에 범용적으로 사용

성능


'AI > CV' 카테고리의 다른 글
| EfficientDet (0) | 2022.03.23 |
|---|---|
| Object Detection Neck (0) | 2022.03.22 |
| MMdetection (0) | 2022.03.22 |
| COCO data 처리 (0) | 2022.03.22 |
| mAP란? FLOPs 란? (0) | 2022.03.21 |


