
꺼내먹는지식 준
Pytorch Backpropagation(AutoGrad, Optimizer) 본문

딥러닝에서 layer를 흔히 레고 블럭에 많이 비유한다.
레이어를 정의한 후, 연결하여 정보를 다음 단계로 넘기는 과정이 마치 레고를 연속적으로 붙이는 것과 유사해서이다.
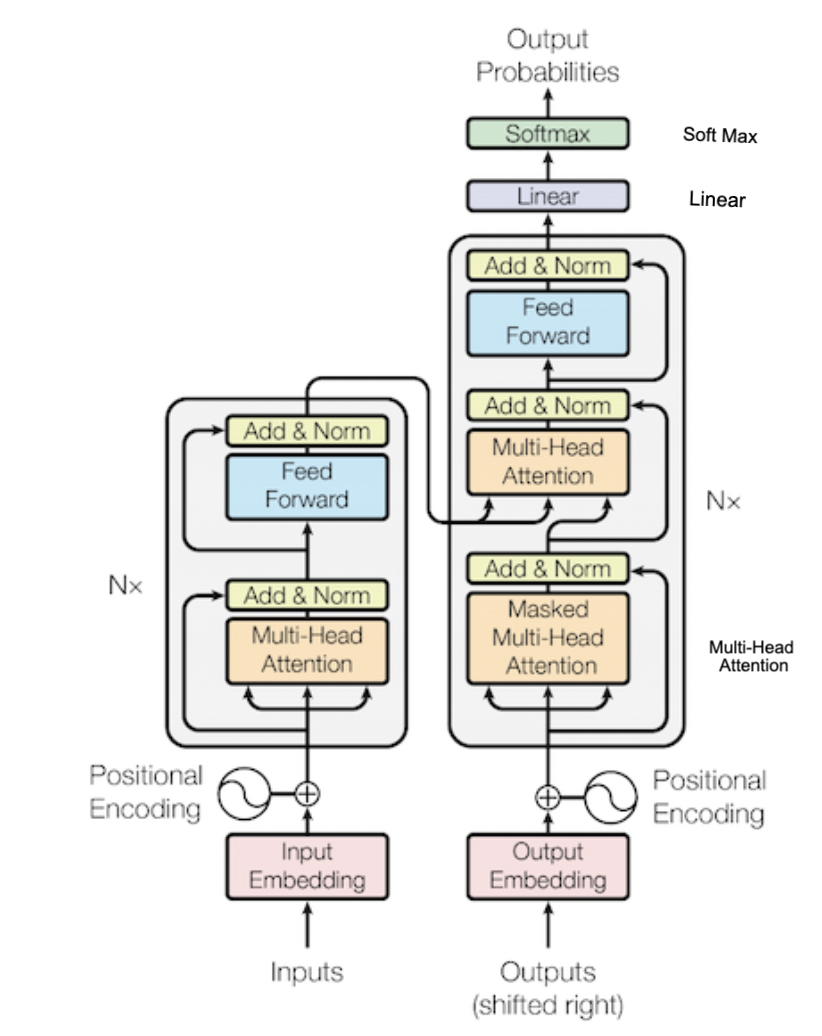
블록 반복의 연속
대표적으로 Transformer만 보아도, Multi-head attention ... Linear, Soft Max 등의 각각의 레이어, 그리고 레이어들이 합쳐져서 하나의 큰 블록을 형성한 레이어들이 합쳐진 구조이다.
Torch.nn.Module
딥러닝을 구성하는 Layer의 base class
기본적으로 정의해야하는 4가지
1) Input 2)Output 3)Forward 4)Backward 정의
학습의 대상이 되는 parameter(tensor) 정의 (Backward Weight)

nn.Parameter
Tensor 객체의 상속 객체
nn.Module 내에 attribute가 될 때는 required_grad = True 로 지정되어 AutoGrad 학습의 대상이 되는 Tensor
우리가 직접 지정할 일은 잘 없다 : 대부분의 layer에는 weights 값들이 지정되어 있음 (nn.Linear, nn.Conv ... etc)

in features가 7, out_features가 5라고 가정할 때, weights 은 7X5형태여야 크기를 맞춰줄 수 있다. Bias 도 paremeter 선언

Backward
Layer 에 있는 Parameter들의 미분을 수행
Forward의 결과값(prediction: model ouput)과 실제값간의 차이(Loss) 에 대해 미분을 수행
해당 값으로 Parameter 업데이트

이전 학습의 gradient 값이 지금 학습에서 영향을 끼치지 않도록 초기화
optimizer.zero_grad()
$\hat{y}$ = model(inputs)
loss값 = criterion($\hat{y}$, y)
파라미터 업데이트
optimizer.step()
model = LinearRegression(inputDim, outputDim)
#모델 선언
if torch.cuda.is_available():
model.cuda()
#GPU 에서 돌리기
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr= learningRate)
#Loss 선언, Optimizer 선언(대상은 model parameters)
Backward from the scratch
잘 사용하지 않지만 Backward는 Module 단계에서 직접 지정 가능하다.
Module에서 backward와 optimizer 오버라이딩
사용자가 직접 미분 수식을 써야하는 부담이 생긴다.

w와 b의 초기값 잘 살펴보자.
.to(device) GPU에 올리기
backward 함수를 보면 직접 편미분 한 수식이 적혀져 있는 것을 알 수 있다.
optimizer 즉, w 값과 b 값이 업데이트 되는 것이 정의되어있다.
'AI > PyTorch' 카테고리의 다른 글
| Torch Indexing (0) | 2022.01.25 |
|---|---|
| Pytorch Dataset (0) | 2022.01.25 |
| Pytorch 프로젝트 생성, 배포, 유지보수 (0) | 2022.01.24 |
| Pytorch 기본기 (0) | 2022.01.24 |
| Pytorch vs Tensorflow (0) | 2022.01.24 |


