
꺼내먹는지식 준
TF-IDF 추천 본문
TF-IDF 는 텍스트를 다루는 가장 기본적인 방법론이다. 이를 기반으로 텍스트 데이터를 활용하여 컨텐츠 기반 추천을 하곤 한다.
우리가 매일 마주치고 인터렉션하는 것이 언어이다보니, 언어 정보를 활용하여 추천을 할 수 있다는 건 당연하다.

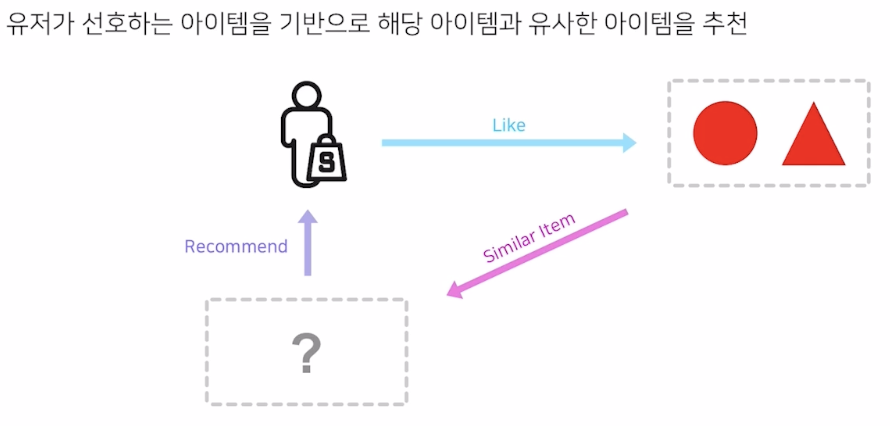


유저가 선호하는 아이템의 특징을 추출하여 user profile 을 만든다. 이를 기반으로 새로운 추천을 해주는 것이 바로 컨텐츠 기반 추천이다.
컨텐츠 기반 추천의 장단점을 살펴보자.

새로운 아이템 혹은 인기도 낮은 아이템 추천이 가능하다는 특징은 "long tail phenomenom" 과 연관
또한 설명가능하다는 점은 사용자가 추천 시스템을 신뢰하는데 굉장히 중요한 요소 $/rightarrow$ HCI 관점
아이템의 적합한 피쳐를 찾는 것이 어렵다. (이미지, 텍스트, 숫자 데이터 등등 일 경우 모두 필요한 feature preprocessing 이 달라진다.) $\rightarrow$ HCI 관점, 폭넓은 AI 이해도가 필요한 이유
한 분야, 장르의 추천 결과만 나올 수 있다는 한계 (collaborative filtering 에서 해결한 문제점)
다른 유저의 데이터 활용이 불가능하다는 점이 단점으로도 적용

Item profile이 공통적으로 가장 표현하기 좋은 형태는 Vector 형태이다.
다양한 아이템 형태들이 존재한다.
그러나 해당 글에서는 유저가 가장 많이 접점이 있는 '텍스트' 데이터만 다루기로 한다.

TF-IDF 는 문서에서 단어의 등장 빈도로 중요도를 선정하는 간단한 방법론이다.
평소에는 잘 등장하지 않는 단어가 특정 문서에서 자주 등장하면 중요도가 높을 것으로 판단되는 것은 당연지사이다. (물론 예외의 경우도 있어 해당 방법론에 대한 대체법들이 나왔지만..)

단어의 등장 횟수는 문서의 길이마다 다를 수 있으므로 normalize 한다.
TF: 타겟 단어 등장 횟수 / 가장 많이 등장한 단어 개수
IDF: $\log \frac{N}{n_w}$ IDF 값은 변화가 커서 smoothing 을 위해 log 를 사용한다.




아래는 예시이다.

여기서 좀 더 develop 하자면, 유저가 rating 을 주었다고 가정하고, 단순히 평균을 내는 것이 아니라 가중치를 두어서 가중 평균을 낼 수도 있다.
user vector 를 구하고 나면, 유사도 검사를 통해 비슷한 아이템을 추천해줄 수 있다.
간단한 예시로 cosine similarity 를 살펴보자.


그러나 단순히 유사도만 보는게 아니라, 선호도 즉 평점을 정확하게 예측하고 싶다면 어떻게 해야 할까?

이는 유저가 기존 평점을 매긴 모든 아이템의 백터를 활용해서 정확한 예측치를 추론한다.
즉, 모든 아이템과 새로운 아이템의 코사인 유사도를 비교하여 얻은 값을 가중치로 하여, 각 평점에 각 가중치를 곱하여 정확한 평점을 예측한다.
예시로 살펴보자.

'AI > 추천시스템' 카테고리의 다른 글
| 고윳값, 고유벡터 (eigen value, eigen vector) (0) | 2022.07.12 |
|---|---|
| Collaborative Filetering - 1 (Neighborhood-based CF, K- Nearest Neightborhood CF) (0) | 2022.07.11 |
| 추천 시스템 공부 로드맵 (0) | 2022.07.05 |
| 연관 분석 추천 (0) | 2022.07.05 |
| 인기도 기반 추천 (0) | 2022.07.05 |



