
꺼내먹는지식 준
Model Serving 개론 본문
용어정리
Serving
서비스화
production 환경에 모델을 사용할 수 있도록 베포
머신러닝 모델을 개발, 현실 세계에서 사용할 수 있도록 하는 행위 (웹, 앱)
Inference
모델에 데이터가 제공되어 예측하는 경우, 사용하는 관점
Serving - Inference 가 혼재되어 사용하는 경우도 존재 (ex. Batch Serving/ Batch Inference)
Online Serving
웹 서버

요청 받으면 요청 내용을 보내준다는 개념은 어렵지 않으나, HTML 문서나 오브젝트를 전달해준다는 뜻이 좀 모호하다.
아래의 예시들을 보자.
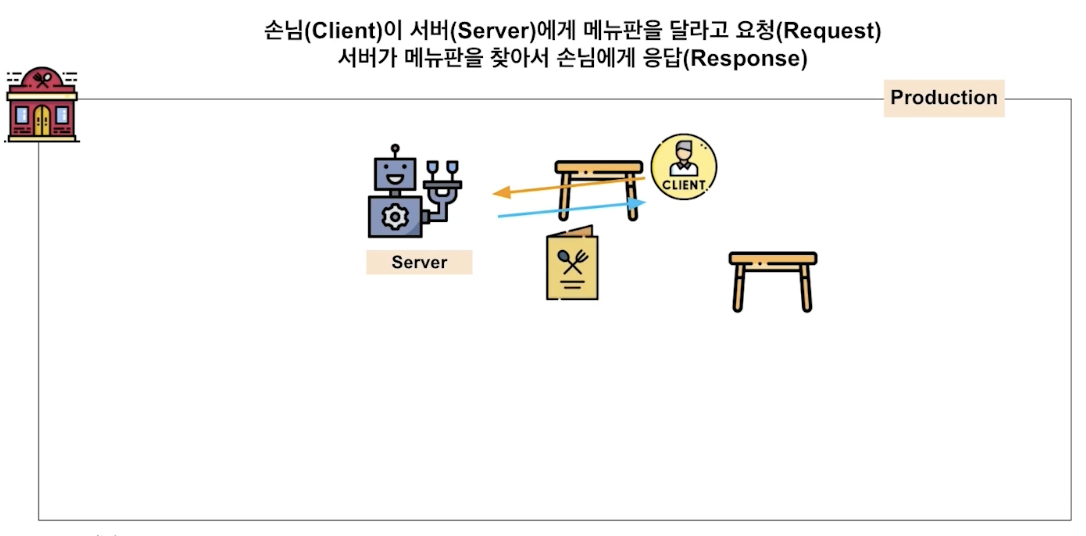
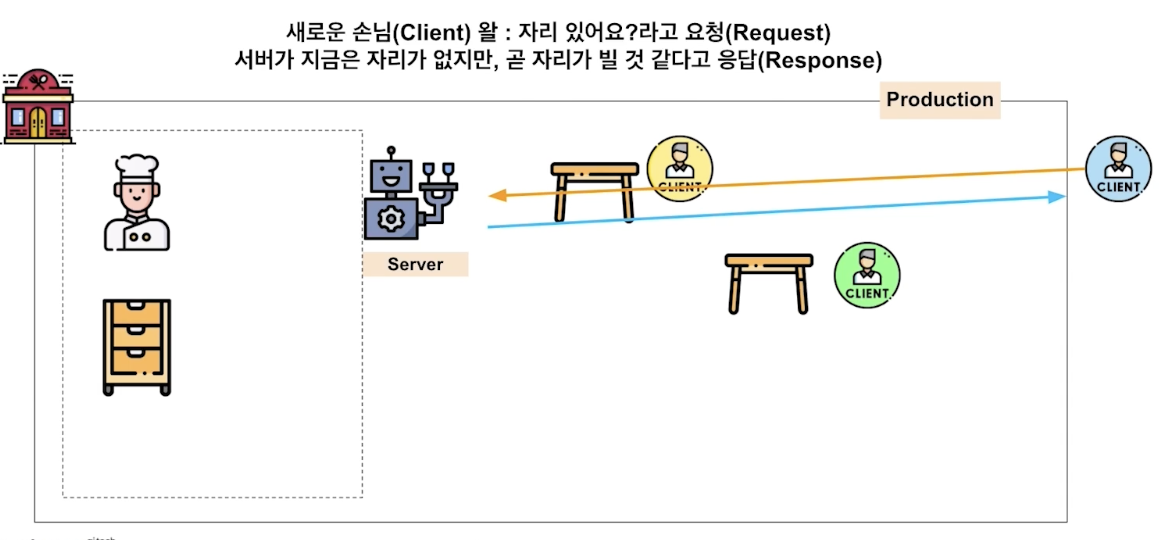

변경도 가능 , 대기 취소 (변경 응답, 취소 응답 )
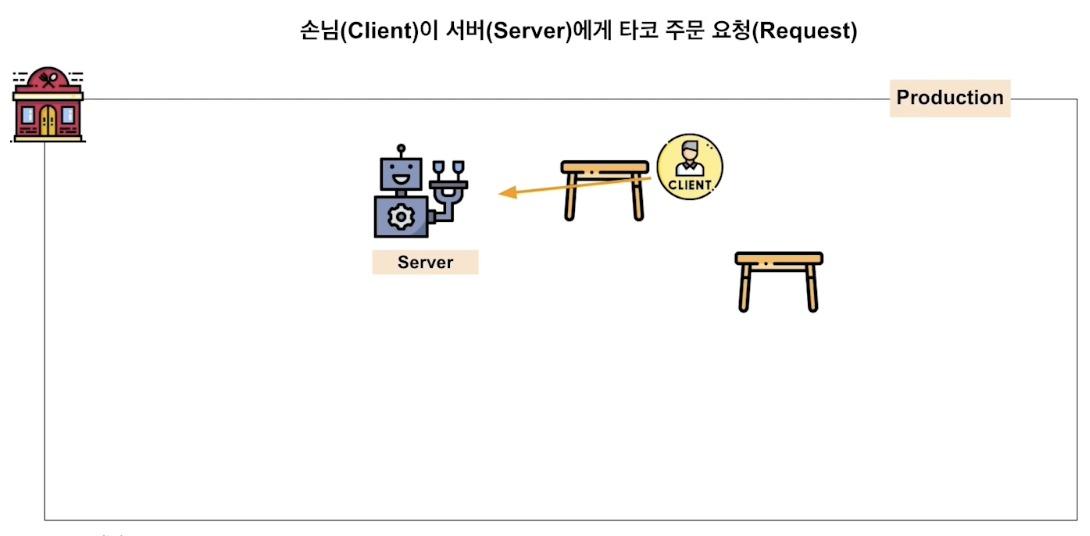

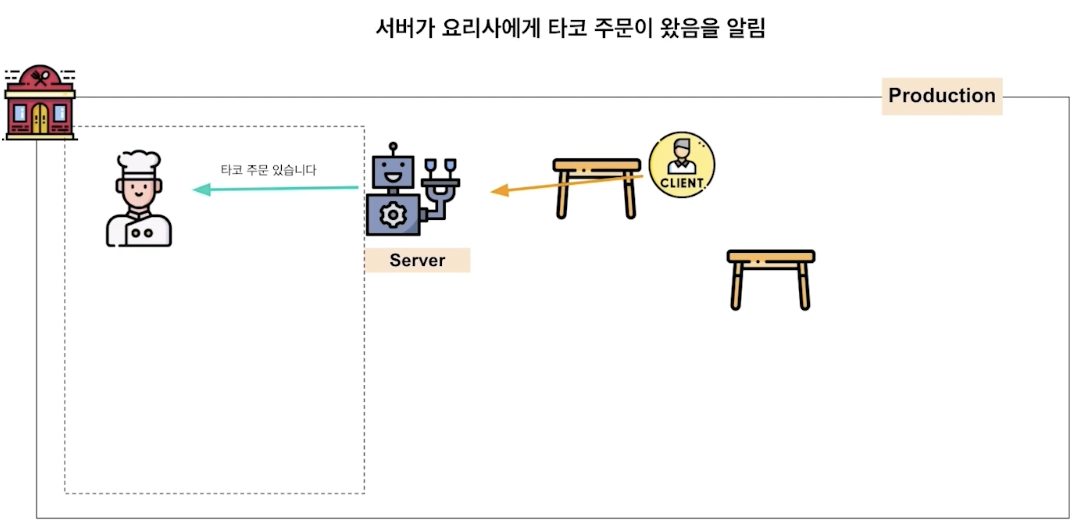
정리하자면 client 의 다양한 요청을 웹 서버가 잘 처리해서 응답으로 제공하는 것이 바로 online serving
예시)
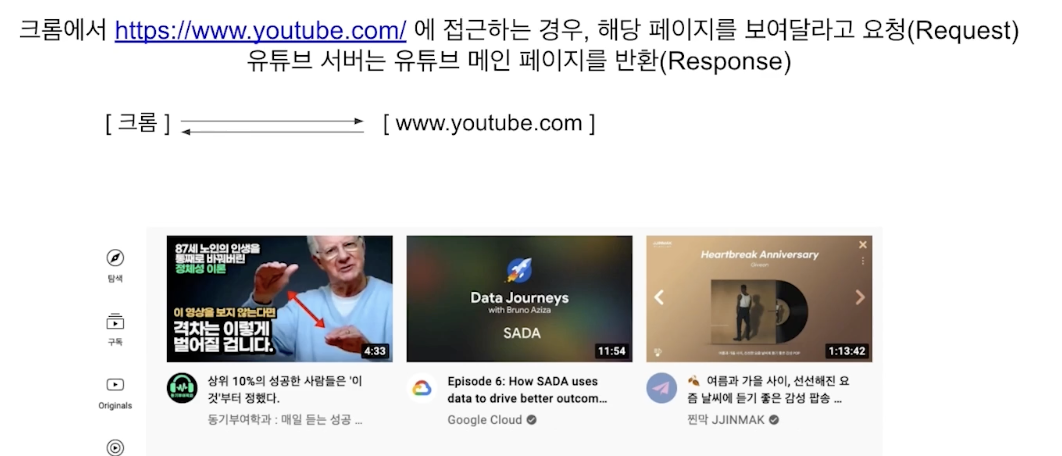


Machine Learning Server 도 결국 Client 의 다양한 요청을 처리해주는 역할
(데이터 전처리, 모델을 기반으로 예측 등 - 이래서 inference랑 혼재해서 사용하는 듯)

API

카카오, 네이버, 구글 등
주로 document 읽으면 쉽게 사용 가능
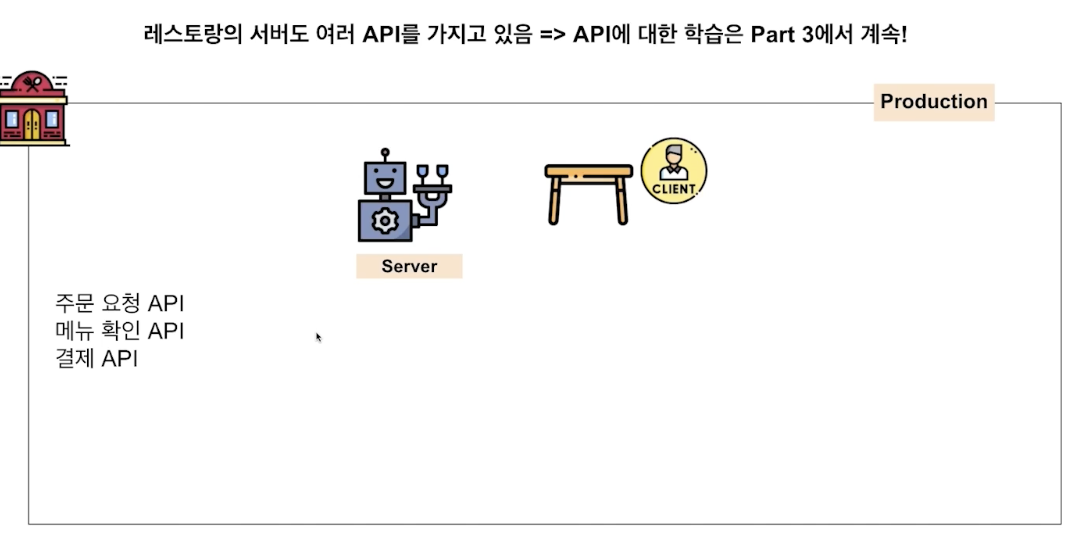
지금 이해한 API는 모듈과 비슷은 한데, 좀 더 큰 범위이자 큰 기능의 집합체 같다.
Inference 관점




서버를 나눌 수도 있다! 경우에 따라서 pipeline 이 복잡할 때는 따로 request 해서 처리하고, 그 처리결과를 local에서 합쳐줄 수도 있을 것 같다.
Online Serving 구현 방식
1) 직접 API 웹 서버 개발
: FLASK, FastAPI 등 사용 서버 구축
서버의 이해가 적으면 어려울 수 있다.
다양한 방식 개발 가능, 매번 추상화된 패턴을 가질 수 있다.
추상화 패턴 잘 제공하는 오픈 소스 활용 방식 --> Serving 라이브러리 활용
2) 클라우드 서비스 활용
: AWS의 SageMaker, GCP의 Vertex AI 등

비용 문제, 익숙해야 한다.
소수의 인원이 많은 업무를 위해서 사용하기 좋다.
내부 구조를 잘 알아야 문제 발생시 해결 가능
사용 과정 통해서 어떤식으로 서버를 구성하는지 알 수 있다.
3) Serving 라이브러리 활용
: Tensorflow Serving, Torch Serve, MLFlow, BentoML 등

예산이 넉넉하면, 일단 클라우드 서비스를 활용해보는 것이 좋다.

Serving 라이브러리를 사용하면 편하지만, 왜 라이브러리를 선택하는지 알기 위해서는 경험이 선 필요하다.
라이브러리에 종속되면 바뀌면 끝이다.
High level을 먼저 사용하지 말고, Low level의 이해도를 먼저 쌓자.
필수
재현 가능하도록 하기 위하여

실시간 예측이 필요한 경우 지연 시간을 최소화 해야 한다.
Latency: 하나의 예측을 요청하고 반환 값을 받는데 걸리는 시간
배달 앱에서 음식 추천을 받기 위해 1분을 기다릴 수는 없다!!!
Online Serving 고려 사항

이 경우 시간이 좀 더 걸린다.

시간을 위해 경량화 된 모델을 사용하는 것이 필요할 수도 있다.

말이 안되는 상황에 대한 후처리 로직이 필요할 수도 있다.
Batch Serving


원하는 컨디션에 따라 주기적으로 모델을 학습하는 방법

학습과 예측을 별도로 처리할 수도 있다.
예시

다음의 경우들에서 활용이 가능하다.


그러나, Cold Start issue가 크게 문제가 되는 시나리오가 보이지 않는다.

예측을 1주일 단위로 하는 것 Discover Weekly, 오히려 실시간성보다 좋은 서비스

스포티파이의 그래프
Workflow Scheduler
모델의 활용 pipeline

Online vs Batch : Input의 관점
데이터 하나씩 요청의 경우 Online
여러가지 데이터가 한꺼번에 처리되는 경우 Batch!
Output 관점
인퍼런스 output을 어떻게 활용하는가?
API 형태로 바로 결과를 반환해야 하는 경우: Online
서버와 통신이 필요한 경우: Onlien
1시간에 1번씩 예측해도 괜찮은 경우: Batch

추가 고려 사항
우리의 모델은 Online Serving 을 해야 한다.
(그 외에도 클라이언트에서 모바일 기기, IoT Device등 Edge serving 도 존재)
'AI > MLOps' 카테고리의 다른 글
| Product Serving 해보기 2 - Streamlit (0) | 2022.05.17 |
|---|---|
| Product Serving 해보기 1 - Voila (0) | 2022.05.17 |
| MLOps 개론 (0) | 2022.05.16 |


