
꺼내먹는지식 준
MLOps 개론 본문
MLOps 개론
모델 개발 과정은 다음의 순서를 따른다.

1) 해당 과정은 자신의 컴퓨터, 서버 인스턴스에서 주로 실행
2) 고정된 데이터를 사용해 학습
3) 학습된 모델을 앱, 웹 서비스에서 사용할 수 있도록 만드는 과정 필수
3) 번 과정을 Real World, Production 환경에 모델을 배포한다 표현

모델이 배포된 후, Deploy 과정이 생성된다.
이 경우 발생 문제
1) 모델의 결과값이 이상한 경우가 존재
원인 파악, input 데이터가 예측 못한 형태인 경우, Research 와는 다르게 outlier 처리 불가능
2) 모델의 성능이 계속 변경
정형 데이터에서는 정확히 알 수 있으나, 비정형 데이터(이미지)는 알기 어려울 수 있다.
예측 값과 실제 레이블을 알아야 한다.
3) 새로운 모델이 더 안 좋은 경우
과거의 모델을 사용해야 하는가?
Research와 실제 상황에서 SOTA 모델은 바뀔 수 있다.
MLOps
머신러닝 모델링 코드는 머신러닝 시스템 중 일부에 불과함
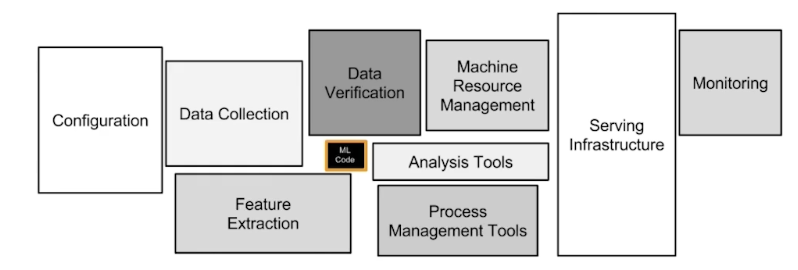
MLOps = ML + Ops (Operations)
머신러닝 모델을 운영하면서 반복적으로 필요한 업무를 자동화시키는 과정
머신러닝 엔지니어링 + 데이터 엔지니어링 + 클라우드 + 인프라
$\rightarrow$ 머신러닝 모델 개발과 머신러닝 모델 운영에서 사용되는 문제, 반복을 최소화하고 비즈니스 가치를 창출하는 것이 목표
모델링에 집중할 수 있는 인프라 생성, 자동으로 운영되도록 만드는 일
MLOps 의 목표: 빠른 시간 내에 가장 적은 위험을 부담하며 아이디어 단계부터 Production 단계까지 ML 프로젝트를 진행 할 수 있도록 기술적 마찰을 줄이는 것
내가 이해한 말로 정리하자면 실제 서비스 "기획" 을 하는 건 아니지만, 기획이 기술적으로 잘 구현될 수 있는지 확인 및, 그리고 모델 서빙을 위한 생태계 구축 정도로 보인다.


워낙 다양한 library가 존재하므로, 문제를 해결하는 방법론에 집중을 해야 한다.
MLOps component

타코를 비유로 들면 이해하기 좋다.
집에서 만드는 타코가 맛있어서 창업을 한다면, 아마 들어오는 데이터부터가 그 전이랑은 좀 다를 것이다.
또한 이제는 집에서 만들때와 다르게, 타코를 만드는 행위외에 고민해야할 것들이 많이 생긴다.
유동 인구, 가게 평수, 점포 확장 등이다.
MLOps 도 이와 같다.
예측되는 트래픽, CPU, Memory 성능, 스케일 업 여부, 자체 서버를 사용할지 클라우드를 사용할지 등이다.
이 중에서 prototype 형태로 모델을 서빙할 때 가장 중요한 것은
1) CPU, Memory 성능
2) 자체 서버를 사용할지 클라우드를 사용할지
로 보인다.

Production 환경에서는 투자방식이 다를 수 있다. 마찬가지로 클라우드를 구매하지 않고 임대하기도 한다 .


Serving
요리가 완성되면 serving 을 해야 한다.


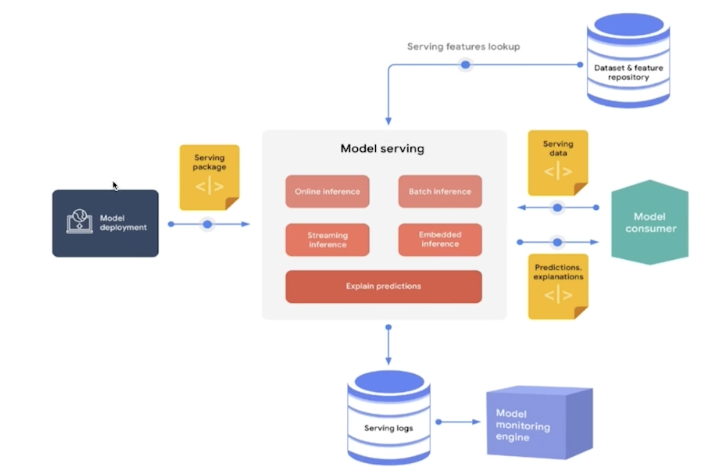
여러 시행착오를 겪으며 요리한다. (머신러닝 모델링도 많은 실험을 한다.)
요리 레시피를 기록하듯이, 베스트 성능 하이퍼 파라미터를 잘 정하고, 전달해야 한다.
요리부산물 (pickle, pth 파일 등)
또한 모델 정보도 잘 기록해둠으로써 잘 관리한다.
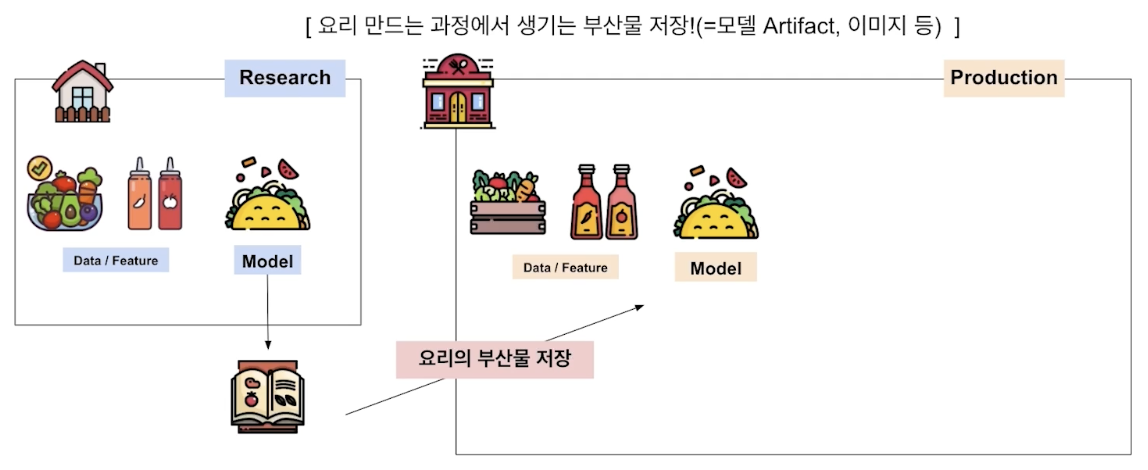

모델이 많아질 수록, 기록하기 힘들다. 이에 따라 코드에서 자동으로 기록되도록 해야 한다.
모델을 배포하고자 할 때도, 해당 정보들을 확인할 수 있어야 한다.
대표적 library: MLflow
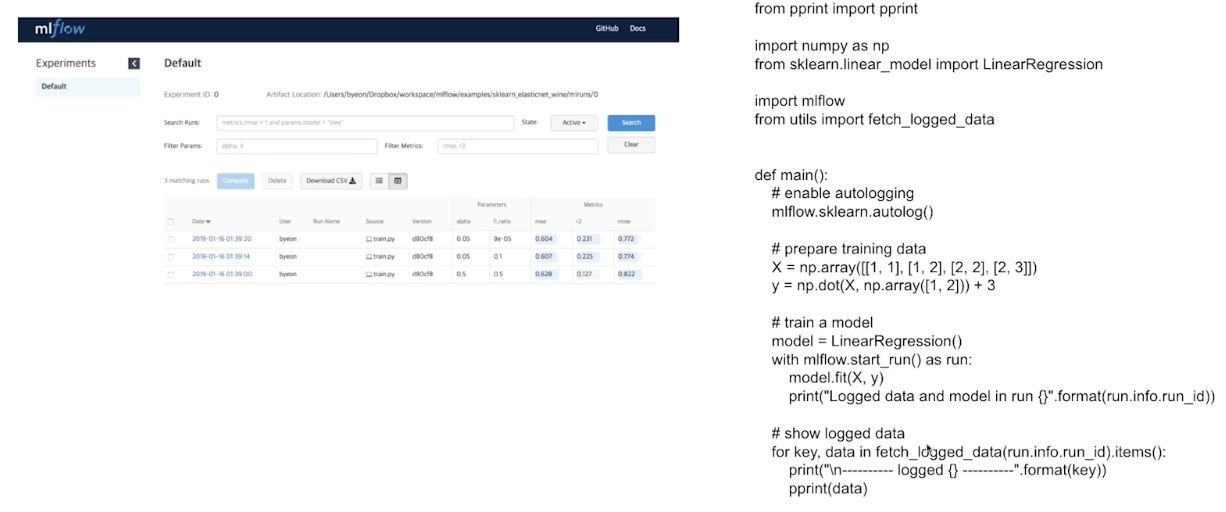
지정 안해도 알아서 저장이 된다.


요리시 재료를 미리 준비하는 것 처럼, 머신러닝 feature를 미리 저장해놓고 추출해오면 전처리 시간을 줄일 수 있다.
tabular, 정형 데이터에서 주로 사용된다.
집과 레스토랑에서 같이 사용할 수 있도록 정보 공유가 원할하면 좋다.


feature vector 를 가져오는 모듈, 사용도 간단하다.
하지만, 많이 사용하지는 않는다.
Data- Drift, Model Drift, Concept Drift
학습시 사용한 데이터(feature)와 production의 데이터(feature) 분포를 비교해야 한다.
데이터 변화를 보여주는 library (TFDV: tensorflow만 지원)

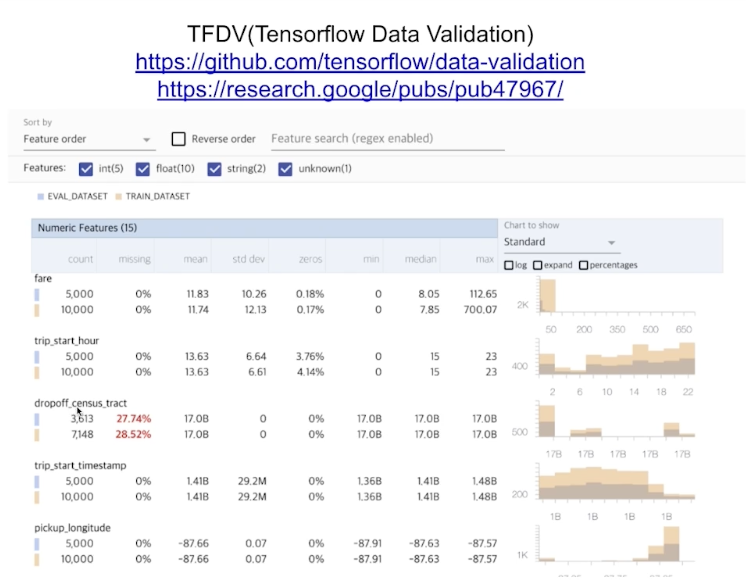
AWS Deequ: Scalar coding이긴 하지만, 데이터의 로직 체크

Continous Training
모델이 잘 작동하지 않거나, 정규적으로 모델을 다시 학습하거나 , 수정할 수 있다.


모니터링으로 모델의 결과를 분석해서 앞으로의 방향성을 정할 수 있다.

데이터만 줘도 모델을 만드는 모델
NNI 실험 관리도 같이 하는 hyper parameter autoML


ML Ops 는 새로운 분야라 계속해서 새로운 분야가 나타날 수 있다. 계속해서 새롭게 등장하는 component를 tracking하자!

처음부터 모든 component를 구현하는 것이 아니라, 뭐가 필요할까? 어떤게 도움이 될까? 를 고민해서 필요한 것을 하나씩 사용하는 것이 중요!
아래 자료 참고!


'AI > MLOps' 카테고리의 다른 글
| Product Serving 해보기 2 - Streamlit (0) | 2022.05.17 |
|---|---|
| Product Serving 해보기 1 - Voila (0) | 2022.05.17 |
| Model Serving 개론 (0) | 2022.05.17 |


