
꺼내먹는지식 준
프로그래머스 LV 1 정리 본문
코딩테스트의 기본 문제들을 스킵하고 바로 골드 문제에 뛰어든 나는 기본기의 필요성을 항상 느꼈다.
똑같은 구현도 시간이 배로 든다.
이에따라 프로그래머스 모든 문제 풀이에 도전한다.
3일전부터 프로그래머스 LV1을 풀었고, 풀면서 마주했던 테크닉, 혹은 기억하고 싶은 부분들을 기록한다.
1. 정규식 사용
https://kibua20.tistory.com/199
Python 정규식(Regular Expression) re 모듈 사용법 및 예제
정규식 표현식(Regular Expression)은 문자열을 처리하는 방법 중 하나로 "특정 조건 또는 패턴"을 치환하는 과정을 쉽게 처리할 수 있는 방법입니다. Python에서 정규식 처리 모듈은 re 로, re 모듈에 대
kibua20.tistory.com
''.join(re.findall('[a-z]|\d|[-_.]', answer))
정규식 중 가장 많이 사용하게 될 것으로 보이는 것은 바로 findall 이다.
'[a-z]': a 부터 z 까지
| or
\d 정수
| or
[-_.] 해당하는 char - _ .
을 answer로부터 모두 찾아 list 의 element로 반환한다.
※string에서 간단하게 대체하는 방법으로는 replace 가 있다. 하지만 이는 모든 원소를 다 대체해버린다는 걸 유의.
>>> a = '123456789111'
>>> a.replace('1', 'A')
'A23456789AAA'2. 연속하는 원소 찾기
많은 문제에서 연속하는 원소를 찾아야 할 경우가 발생한다.
2가지의 풀이를 확인했다.
1) 해당 원소와 다음 원소 비교
if answer[i] == '.' and answer[i+1] == '.':원소 비교시, 현재 원소와 다음 원소를 비교하는게 구현이 가장 깔끔하게 떨어진다.
2) zip 을 사용한 비교
for a, b in zip(words, words[1:] + ['']):zip으로 현재 list와 list에 원소 하나를 추가해서 비교한다.
해당 방법의 가장 큰 장점은 1번 방법의 경우 마지막 원소는 방문하기전에 iteration이 마감되어 마지막에 명시적으로 방문을 해야한다.
마지막 원소에 ' '를 추가하여 zip으로 묶어주게 되면 마지막 항도 한번에 방문할 수 있으므로 코드가 좀더 깔끔하다.
3. Lambda 와 map의 결합
i번째 숫자부터 j번째 숫자까지 자르고 정렬했을 때, k번째에 있는 수 문제에 대한 구현을
def solution(array, commands):
answer = []
for (i,j,k) in commands:
tmp = sorted(array[i-1: j])[k-1]
answer.append(tmp)
return answer다음과 같이 한줄로 구현할 수 있다.
return list(map(lambda x:sorted(array[x[0]-1:x[1]])[x[2]-1], commands))map 함수로 commands의 리스트들을 각각을 x 에 map 한 후, x[0] - 1 : x[1] 까지의 자른 원소들을 sort 한 후, 그 중 x[2] - 1 번째 원소를 찾아내어 list화한다.
이해는 잘 가지만 현실에서 해당 코드가 유연하게 나올지는 잘 모르겠다.
파이썬에서 코딩테스트를 풀 때 대표적으로 유용한 library 두개가 바로 intertools 와 collections 이다.
4. Itertools - cycle
>>> from itertools import cycle
>>> cu = cycle([1,2,3,4,5,6])
>>> cu
<itertools.cycle object at 0x100d827c0>
>>> cu[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'itertools.cycle' object is not subscriptable
>>> next(cu)
1
>>> next(cu)
2다음과 같이 구현하며 element에 직접적으로 접근하기 위해서는 next() 함수를 사용해야한다.
>>> for i in cu: print(i)
...
3
4
5
6
1
2
3
4
5
6
1
2
for 문에 넣고 돌리면 해당하는 원소들이 무한적으로 반복되는 것을 알 수 있다.
무한 반복의 list 가 필요한 경우 사용하면 좋다.
5. collections - Counter
Counter는 아주 자주 활용되는 모듈이다. 리스트 내의 원소의 개수를 count해줄 뿐 아니라 덧셈 뺄셈 연산도 지원한다.
>>> a = [1,2,3,3,2,2,1,2,3]
>>> b = [1,2,3,5]
>>> a = Counter(a)
>>> b = Counter(b)
>>> a - b
Counter({2: 3, 3: 2, 1: 1})해당 기능에서 아주 유용한 부분은 바로 a 에 없는 5를 b가 가지고 있더라도 문제 없이 직관대로 셈을 할 수 있다는 점이다.
※set
오히려 Counter보다도 더 많이 사용되는 module
리스트안에 반복되는 원소가 있다면 제거해준다.
>>> a = [1,2,3,1,2,3,2,3,2,3,2,2,3,4,5]
>>> set(a)
{1, 2, 3, 4, 5}
>>> b = [1,2,3]
>>> set(a) - set(b)
{4, 5}set 도 연산을 지원한다. list는 왜 연산을 지원하지 않을까?
이는 바로 list 내부에는 겹치는 원소들이 존재하기 때문이다.
[1,1,2,3] - [1] 이 모든 1을 제거하라는 건지, 1을 하나만 제거하라는건지에 대한 의사결정이 이뤄질 수 없으므로 연산이 불가능하다.
6. 제곱수
제곱수의 약수의 개수는 홀수이고, 제곱수가 아닌 경우는 짝수이다.
예를 들어 제곱수인 4, 16은 모두 약수의 개수가 홀수이다.
이는 2, 4 와 같이 제곱근이 존재하기 때문이다.
위의 방법으로 제곱수의 개수를 구할 경우 유용하게 찾을 수 있다.
7. 약수
약수를 구할 때 흔히들 target 원소 N까지의 모든 정수를 iteration하며 나머지가 0인 원소를 찾는다.
해당 방법은 비효율 적이다.
효율적인 2가지 방법을 소개한다.
1) 절반
(N // 2) + 1target 원소의 절반까지만 iteration 하며 나머지가 0인 원소를 찾는다.
예를 들어 32의 경우 32의 절반인 16까지만 확인해도 충분하다. 이미 32는 1에서, 16은 2에서 검출된다.
1 2 4 8 16 32
2) 제곱근
int(math.sqrt(N)) +1
int(N ** 0.5) +1target의 재곱근까지만 iteration하며 나머지가 0인 원소를 찾는다.
예를 들어 16의 경우 4까지만 확인하면 1에서 16, 2에서 8, 4에서 4를 검출하여 모든 원소를 확인할 수 있다.
1 2 4 8 16
32의 경우에도 32의 제곱근인 5.656를 검출할 수 있다. 이 때 안전하게 정수화하고 1을 더해준다. 5+1 = 6
1 2 4 (6) 8 16 32
6까지만 interation을 돌아도 1에서 32, 2에서 16, 4에서 8을 찾기에 모든 원소를 확인할 수 있다.
사실 버리고 1을 더해주지 않아도 되지만 안전하게 하기 위하여 더한거니 참고하면 되겠다.
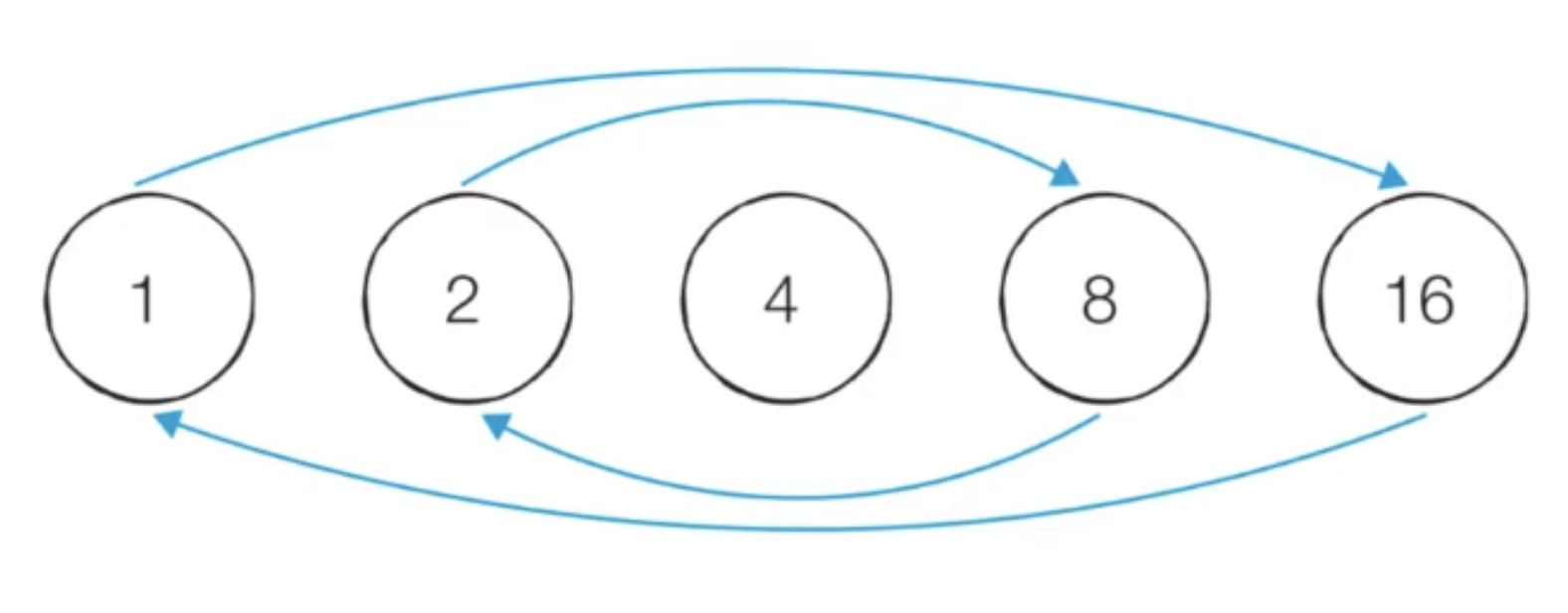
※해당 문제는 소수 찾기에서도 탐색 공간을 (N ** 0.5) +1 로 줄일 수 있다.
8. 최소 공배수, 최대 공약수
위에서 약수를 수월하게 구하는 방법을 공부했으므로 이제는 최소 공배수와 최대 공약수를 효율적으로 구할 수 있다.
최대 공약수의 경우
a = 12 b = 16
for i in range(1, int(a ** 0.5) + 1):
if a % i == 0 and b % i == 0:
answer = i다음과 같이 더 작은 수에 맞춰 곂치는 약수를 찾으면 된다.
최소 공배수의 경우
a * b / 최대공약수
12 * 16 / 4
= 48로 아주 간단하게 해결 가능하다.
최대 공약수의 경우 유클리드 호제법이 있지만, 관심없다. 그거까지 몰라도 이미 충분히 효율적이다.
※원소의 위치 바꾸기
문제를 풀다보면 a, b 가 주어졌을 때 문제의 효율적 해결을 위하여 a 에 무조건 b보다 큰 원소를 넣고싶을 때가 있다.
기존 정규 과정에서는
if a < b:
tmp = a
a = b
b = tmp와 같은 방법을 사용했지만,
if a < b: a,b = b,a로 더 간단하게 사용하자.
9. n진법
n 진법에서 10진법으로, 10진법에서 n 진법으로 간단하게 옮겨가는 방법들이 있다.
1) n 진법에서 10진법으로 이동
# 3진법 1001 > 10 진법
num = '1001'
decimal = 0
tmp = 1
for i in (num[::-1]):
decimal += int(i) * tmp
tmp *= 3
#decimal : 28
구현상 가장 간단한 방법이지만, 우리에게는 int를 사용하는 방법이 있다.
num = '1001'
decimal = int(num, 3)
#decimal : 28int 를 사용하면 n 진법에 대해 빠른 계산이 가능하다.
2) 10진법에서 n 진법으로 이동
# 28 에서 3진법으로 이동
decimal = 28
third = ''
while(decimal == 0):
third += str(decimal % 3)
decimal //= 3굳이 str을 사용하는 이유는 만약 list 를 만들어서 append 할 경우 [ 두번째 자리 ,첫번째 자리] 다음과 같은 형태, 즉 우리의 기대와 반대로 원소가 들어가게 되고 join해주는 과정에서 순서를 한번 더 뒤짚어 줘야 한다.
이에 따라 str을 활용하여 순차적으로 붙여주고 추가로 join해줄 필요성을 없앤다.
※10진법에서 2진법으로 이동
가장 많이 사용되는 10진법의 경우 2진법으로 쉽게 이동하는 내장 함수가 있다.
>>> bin(123)
'0b1111011'다만 앞의 '0b' 는 버리고 사용해야 한다.
10. 알파벳 순서
ord $\rightarrow$ chr
대단한 기능은 아니지만, 때때로 유용하다.
>>> ord('C')
67
>>> chr(67)
'C'이 기능을 모르면 list 혹은 dictionary에 모든 알파벳의 순서를 나열해야 한다.
alpha = 'abcdefghijklmnopqrstuvwxyz'
up_alpha = ''
for i in alpha:
up_alpha+= i.upper()11. 등차수열 합
등차 수열의 합 문제를 마주하면 보통 $\frac{n*(n+1)}{2}$ 식을 떠올리곤 한다.
하지만 다음의 두가지 이유로 해당 식을 용이하게 사용하기 어려울 수 있다.
1) 원소의 시작이 1이 아닌 경우
해당 경우는 [start :end] 를 더한 후 [1: start)를 빼면 되지만, 시작 지점이 -1 인 경우에는 어떨까?
시작지점과 끝 지점이 모두 음수인 경우에는?
이로인해 이럴 때는 더 간단하게 해결하는 방법이 있다.
sum(range(start,end+1))흔히 range에 음수를 넣을 수 있는지 몰라서 발생하는 이슈이다.
2) Delta 값이 1이 아닌 경우
이 경우에도 range로 간단하게 해결이 가능하다.
>>> sum(range(-10, 20, 3))
35사실 이 경우도 O(n) 으로 나쁘지 않은 알고리즘이지만,
더 간단하게 수식을 사용하는 방법도 있다.

위 수식은 등차, 아래 수식은 등비 수열의 공식이다.
a는 첫 항인 제 1항, l은 마지막 항인 제 n항이다.
즉, range(-10, 20, 3) 의 경우
-10, -7, -4, -1, 2, 5, 8, 11, 14, 17 로
(-10 + 17) * 10 / 2 = 35
아까와 동일한 값은 constant 번만에 구할 수 있다.
12. 2D array의 합
제목은 2D array의 합이지만, 실상으로는 zip 과 numpy 에 대해 간단하게 다룰 것이므로 아주 중요한 개념이다.
a = [[1,2], [3,4]]
b = [[5,6], [7,8]]다음의 array의 axis 1 에 해당하는 원소끼리 더해보자.
첫 번째 방법은 zip 을 활용한 방법이다.
answer = [[i+j for i,j in zip(x,y)] for x,y in zip(a,b)]
여기서 유의할 점은 만약 bracket이 없다면 branch(if, for .. etc) 의 적용 순서는 $\rightarrow$ 이다. 즉 왼쪽에서 오른쪽이다. 하지만 위와 같이 2D의 경우 낮은 차수부터 처리한다.
두 번째 방법은 numpy 를 활용하는 방법이다.
import numpy as np
answer = (np.array(a) + np.array(b)).tolist()numpy 화 한 후, 더해주고 답이 요구하는 형태가 list라면 tolist() 로 변환해준다. 다만, numpy는 사용이 불가능한 경우도 있으니 유의하자.
13. Sort
Sort에는 몇가지 살펴볼게 있다.
1) sort(), sorted() 의 차이
sort()는 return 값이 없고, 주어진 변수의 원소의 정렬한다.
sorted(v)는 v의 원소를 정렬하여 return 하고, v의 순서는 건드리지 않는다.
2) reverse, key
>>> A = [11,4,3,12,3,2,5,7,3]
>>> sorted(A, reverse = True)
[12, 11, 7, 5, 4, 3, 3, 3, 2]reverse는 간단하게 오름차순을 내림차순으로 정렬한다.
key는 lambda와 조합해서 주로 사용한다.
>>> A = [[1,3], [2,1], [5,3], [8,7], [9,9], [3,2]]
>>> sorted(A, key= lambda x: x[1])
[[2, 1], [3, 2], [1, 3], [5, 3], [8, 7], [9, 9]]
>>> sorted(A, key= lambda x: (x[1],x))
[[2, 1], [3, 2], [1, 3], [5, 3], [8, 7], [9, 9]]x[1]을 기준으로 정렬하는 것이 가능하고,
(x[1], x) x[1]을 기준으로 먼저 정렬하고, 내부적으로 x를 기준으로 추가정렬을 한다. (x[1]의 정렬은 깨뜨리지 않는다.)
※ lambda 는 map 이랑 결합해서 사용하기도 하고, 많은 경우 굉장히 유용하게 사용된다.
'코딩테스트총정리' 카테고리의 다른 글
| 프로그래머스 stack 짝지어 제거하기 (0) | 2022.05.07 |
|---|---|
| HEAP (0) | 2022.05.05 |
| 프로그래머스 LV2 문자열 압축 (0) | 2022.04.23 |
| 백준 14567 선수과목 (0) | 2022.02.17 |
| 백준 1931 회의실 배정 (0) | 2022.02.17 |

