
꺼내먹는지식 준
Data Augmentation, Transfer Learning, Unsupervised Learning (knowledge distilation) 본문
Data Augmentation, Transfer Learning, Unsupervised Learning (knowledge distilation)
알 수 없는 사용자 2022. 3. 7. 14:44Computer Vision 문제에서 데이터 부족을 어떻게 완화하고 있을까?
Data Augmentation
모델이 데이터를 편식하지 않
을 수 있도록 골고루 분포해 있다면 너무 좋겠지만 실제 데이터는 그렇지 못하다. 대부분 bias 되어 있다.

가운데는 어떤 강의 평균 사진, 오른쪽은 어떤 숲의 평균 사진
해당 영상들은 사람이 카메라로 찍은 구도의 패턴에 따라 정해진 경우가 많다. 이는 트랜드에 따라 바뀐다.
즉, 우리 사용 데이터는 보통 사람이 찍은 거고, 우리가 보기 좋게 bais해서 찍은 사진들이다.
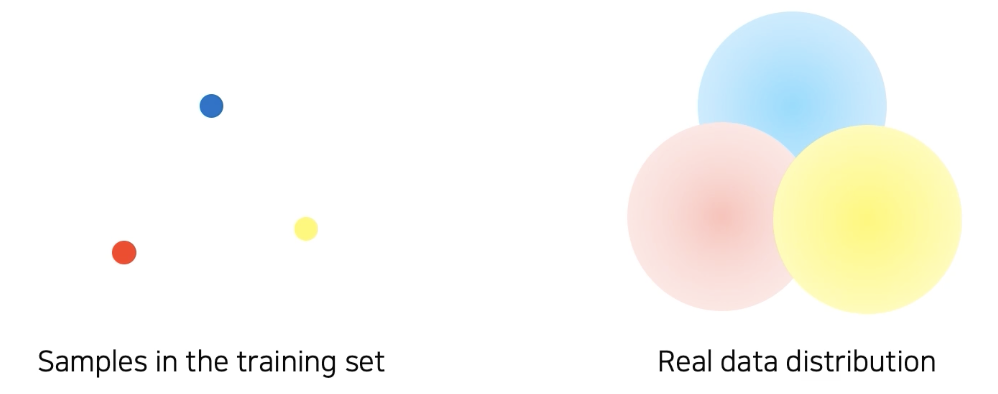
우리가 취득할 수 있는 데이터는 실제 데이터의 아주 작은 양이다. 이로 인해 빈공간이 너무 크게 발생한다.
심지어 bais 까지 되어있다.

왼쪽 밝은 사진으로 학습했는데 오른쪽 어두운 고양이 사진을 만나면 잘 판단할까?
물론 bias되지 않게 사진을 찍으면 좋겠지만, 그게 쉽지 않다.
이로 인해 이러한 빈 공간을 조금이라도 매꾸고자 하는 것이 바로 data augmentation이다.
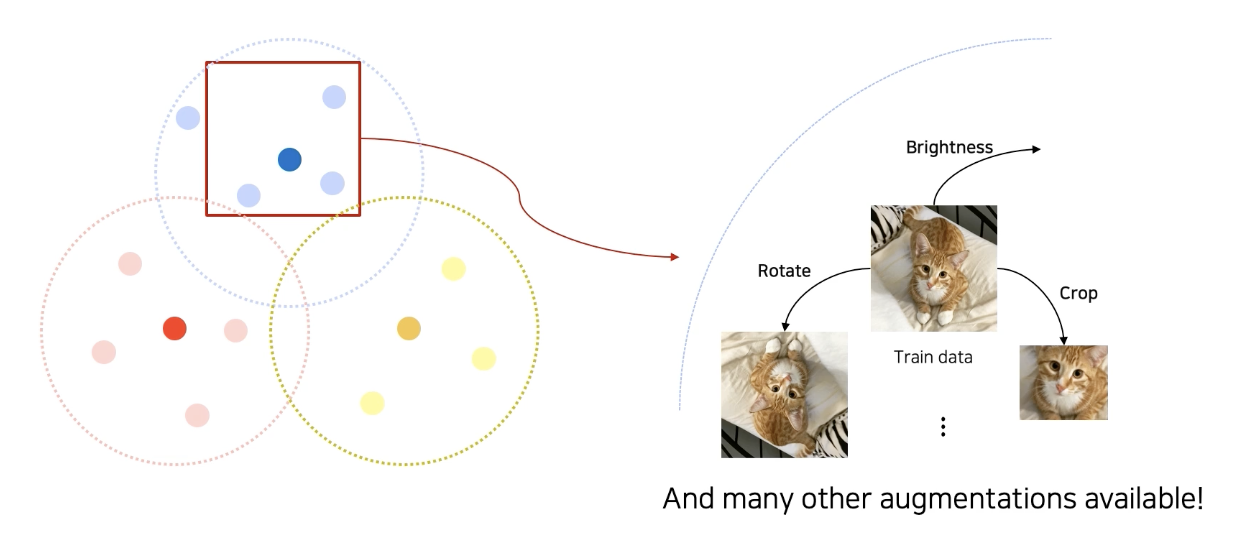
보통은 기존 학습 데이터에 augmentation을 가해서 데이터를 만든다.
crop, sheer, brightness, perspective, rotate 등 ...
OpenCv, NumPy 등 여러 곳에 해당 기능들 존재
Brightness

RGB 값 변경
Rotation
여러방향으로 회전
Crop
강력한 기능 중요한 파트를 더 강하게 학습하도록 한다.
x,y 축 지정범위 내의 color 정보는 포함해라.

Affine Transformation (sheered transformation)
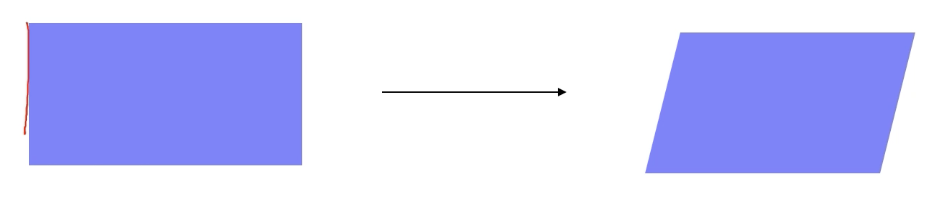
변환 전후, 선은 선으로 유지 되고, 길이의 비율과 평행 관계는 유지하는 것이 아핀 변환

2X2 행렬, translation parameter 2개 총 6개 parameter 필요
입력 영상의 3점에 대해 대응 쌍을 주어서 parameter로 준다.
CutMix

의미 있는 성능 향상, 물체의 위치또한 더 정확하게 catch (label도 섞어줘야한다는점)
RandAugment

어떤 걸 사용, 어떤 순서?
이런걸 정하는 것이 수월치 않고 다 탐색할 수 없으니, random 하게 수행을 해보고 성능이 잘 나오는 것을 가져다 쓰자 즉 이걸 자동으로 search 하는 기법.
어떤 걸, 얼마나 세게 적용할까가 두개의 parameter.

sample a policy: Policy = {N augmentations to apply} by random sampling
Train with a sampled policy, and evaluate the accuracy

손쉽게 성능 향상!
Pretrain, Knowledege Distilation
새로운 task 를 할때는 먼저 dataset을 만들어야 한다. 문제는 어마어마한 데이터가 필요하고, 이 데이터의 label도 필요하다.
즉, 단기간에 대규모 데이터를 수집하는 것도 어렵고, 회사에 하청을 줘도 이상한 결과를 주는 경우가 많다.
이에 따라 가장 획기적이며 좋은 방법이 바로 transfer learning이다.
(공통된 지식이 있을 때)
approach 1

FC layer 만 바꾸고 conv layer는 fix 하고 (freeze) FC layer 만 새로 학습 (적은 데이터만으로도 학습)
approach 2

Conv layer 도 새로 학습을 하긴 하나, 적은 learning rate로 학습, FC layer는 큰 learning rate 물론 첫번째보다는 데이터가 좀더 크지만, 더 강력한 학습 방법
Knowledge distilation
이미 학습된 teacher networker의 지식을 student network에 주입하여 학습하는데 많이 사용
큰 모델에서 작은 모델으로 지식을 전달함으로써 모델 압축에 유용하게 사용 (작은 모델로 큰모델과 비슷한 성능을 내기 위함)
최근에는 teacher 에서 생성된 출력을 unlabled datas의 가짜 레이블 즉 pseudo-labeling 로 자동생성하는 mechanism 으로 사용을 한다. (이해는 가나 더 깊은 이해가 필요할듯) 즉 더 많은 데이터를 사용할 수 있다.

loss 를 통해 student model 만 학습, 즉 teacher 의 distribution 을 모방
label 을 사용하지 않기에, unspervised learning이라고 할 수 있다.
임의의 데이터를 사용할 수 있다.
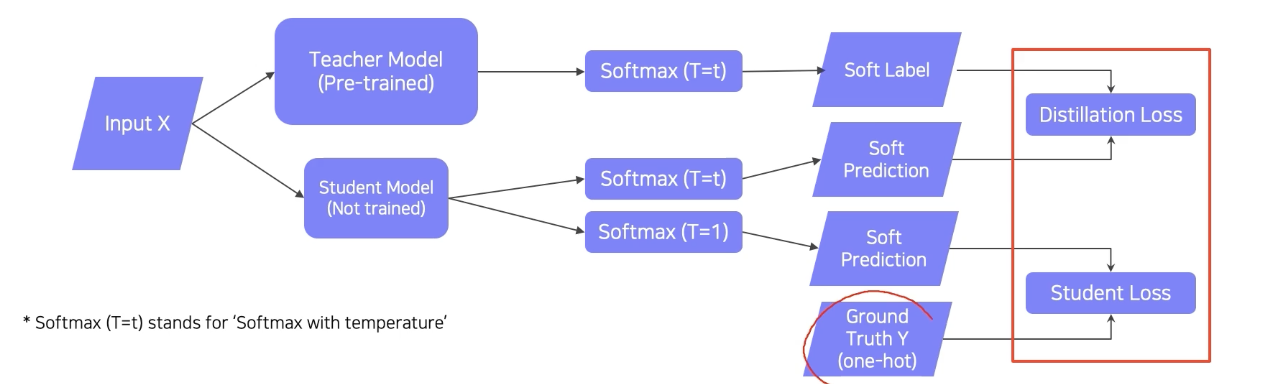

True label까지 있는 경우에는 어떻게 학습을 할 수 있을까?
KL divergence loss = distilation loss

softmax with temperatue(T) Softmax(T=t)


softmax 만 취하면 좀 극단적으로 값이 벌어진다. 하지만 입력 값을 큰 값으로 나눠서 넣어주면 출력을 스무스하게, 즉 중간 값으로 좀 부드럽게 만들어준다. 너무 0과 1에 가까운 값보다는 중간 값도 가지면서 입력에 따라 민감하게 반응하도록 해서 student 가 teacher 를 더 잘 따라하도록 도와주는 역할
(0.1, 0.7, 0.2) 이런식일 때 0.1, 0.2 가 사실 soft prediction이면 반영이 된다. 하지만 이는 그냥 그 자체로의 동작일 뿐이지 semantic 정보는 없다고 한다.

https://light-tree.tistory.com/196
딥러닝 용어 정리, Knowledge distillation 설명과 이해
이 글은 제가 공부한 내용을 정리하는 글입니다. 따라서 잘못된 내용이 있을 수도 있습니다. 잘못된 내용을 발견하신다면 리플로 알려주시길 부탁드립니다. 감사합니다. Knowledge distillation 이란?
light-tree.tistory.com
loss function 참고
label이 있는 데이터를 사용할 때는 distilation loss 와 student loss의 weighted sum 을 통하여 학습한다.
학습은 student model만 학습한다.
Unsupervised Learning (unlabeled dataset for training)
추가적인 label 없이 성능을 올리는 방법은?
label이 필요없는 unlabed data를 쓴다면 internet상의 엄청난 데이터를 사용 가능하다.
Semi-supervised learning은 unspervised 와 Fully labeled 된 fully supervised의 결합이다.
knowledge distilation
label 데이터로 (small-scale) 먼저 pretrain을 한 후, unlabed data의 pseudo label을 이 모델을 통해 짠뜩 생성한다.
그러면 pseudo labeld 된 데이터 셋을 만든다.
이제 기존 데이터와 이 데이터셋을 합쳐서 새로운 모델을 재 학습한다.
굉장히 간단하다!
위 방법론 들을 잘 결합하면 새로운 연구를 만들어나갈 수 있다.
Self-Training
2019년도 imageNet classification에서 엄청난 성능 향상과 동시에 성능 자체가 압도적


ImageNet dataset으로 teacher network 를 학습시켜 놓는다.
pseudo label을 teacher network로 생성을 해서 300M의 unlabeled dataset을 300M의 pseudo dataset으로 만든다.
그 후, 두 데이터 셋을 합쳐서 student model을 학습시키고, 이 때 rand augment해서 더 방대한 양의 데이터를 학습시켰다.
그리고 마지막 step으로 student model 학습이 끝남녀 이전 teacher network를 날려버리고, 최근 학습된 student model을 teacher network 로 사용한다.
그 후, 새롭게 생성된 teacher network로 300M unlabed data set을 다시 pseudo labeled dataset로 relabelling 하고, 새로 student model을 도입해서 두 데이터셋으로 다시 학습하여 새 모델을 만들고, 또 다시 이 과정을 반복한다.
여기서는 student model이 오히려 teacher model보다 조금씩 계속 커진다.

다음의 과정 반복