
꺼내먹는지식 준
Model 본문

모델의 학습을 위한 파이프라인에서 해당하는 곳까지 왔다.
모델이란?
모델은 사람, 물체, 혹은 시스템의 정보의 표현이다.
모델을 만들기 위하여 Pytorch 를 사용한다.
(모델 설계 사용 과정, 학습 과정)
Pytorch
장점: 자유롭고, pythonic 하고, 공부, 연구에 적절

Low - Level, Flexibility
: 리모컨도 한번만 보면 쉽게 사용한다.
하지만 오른쪽도 리모컨이라고 해도, 어떻게 사용할지 감이 잘 안온다.
말을 안해주면 리모컨인줄도 모른다.
이런 관점에서 봤을 때 왼쪽이 더 편리하나, 만약 특정 기능을 추가하려면 어디가 더 편할까?
왼쪽은 이미 완성되어서 분리가 어렵다. 하지만 오른쪽은 기능 추가가 간단하다.
pytorch는 오른쪽에 해당한다.
따라서 새로운 기능 추가가 간단하다.

keras와 pytorch 를 보면 확실히 길이부터도 다르다.
pytorch는 쉽게 바로 파악하기가 어렵다. $\rightarrow$ 특정 batch를 건드리는 것도 간단하다.
keras는 누군가 그런 기능을 만들었다면 하고 기대할 수 밖에 없다.
nn.Module

pytorch 는 module들을 가져오기 간단하게 nn.Module이라는 클래스가 제공되어있다.
conv1, conv2 : 저장소 같은 개념

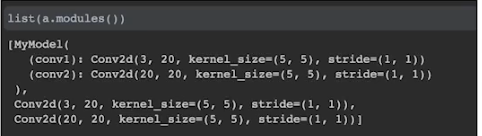
print(model()) 은 init 함수에서 정의한 멤버 모델을 표시한다.
list(model().modules()) 모델들을 생성하며 뱉어내는 함수
(Returns an iterator over all modules in the network.)
modules 로 모델을 저장하고 불러올 수도 있다.
(class, 해당 안의 모듈들까지 다 반환)
forward 선언법 사용법

a(x) == a.forward(a)
모든 nn.Module은 chile modules을 가질 수 있다.
모델을 정의하는 순간, 그 모델에 연결된 모든 module을 확인할 수 있다.
연결되기에 backward 도 연결되어 역전파가 된다.
(각각의 conv1, conv2 에도 forward가 들어있다. )
state_dict

모델 내의 파라미터 관측 가능 state_dict는 key 값과 같이 반환
grad, requires_grad 활용을 통해 layer freeze가능 (Pythonic하다.)
Pretrained Model
매번 좋은 모델 설계하기는 어렵다.
즉, 기존 페이퍼에서 잘 만들어진, SOTA를 달성한 모델들을 가져와서 잘 학습된 weight를 활용하면 좋다.
pretrained model을 사용하면, 기존 데이터 부족했던 아쉬움을 조금은 해소할 수 있다.
저명한 사람들의 모델 구조를 바로 쓸 수도 있어서 너무 유용하다.
Computer Vision의 발전으로 많은 일을 자동화 할 수 있다.
Yolo 실시간 detecting이 되기에 굉장히 편리하다.
segmentaion도 마찬가지다.
발전의 원동력은 무엇일까?
IMAGENET 데이터 셋이 만들어 진 후, 연구의 발달이 엄청났다.
$\rightarrow$ 약, 1400만개의 이미지, 2만개의 category.
즉 좋은 데이터가 정말 중요하다.
이 후, image classification 등의 scoring 점수가 비약적으로 성장했다.

지금에 와서는 인간보다 더 잘 맞추는 경지에 올라있다.
Pretrained Model
당연히 탑 5 모델들은 image 넷으로 학습을 했다. 이에 따라 빌려오기만 해도 된다.
매번 모델 일반화를 위해 수 많은 이미지를 학습시키는 것은 까다롭고 비효율적이다.
좋은 품질, 대용량 데이터로 미리 학습한 모델
$\rightarrow$ 이 모델을 바탕으로 내 목적에 맞게 다듬어서 사용
미리 학습된 좋은 성능이 검증되어 있는 모델 사용시, 시간적으로 매우 효율
TorchVision:
$\rightarrow$ TIMM: 더 많은 실험 등 ..

pretrained = True $\rightarrow$ pretrained weight 까지 같이 다운 받는다.
어떤 방식으로 활용할 수 있을까?
이미지넷은 기존 1000개의 classification을 하는 구조이다.
해당 구조들을 우리 문제에 가져와서 맞춰 수정하면 된다. 이를 transfer learning 이라 한다.
주의 사항
CNN base 모델 구조
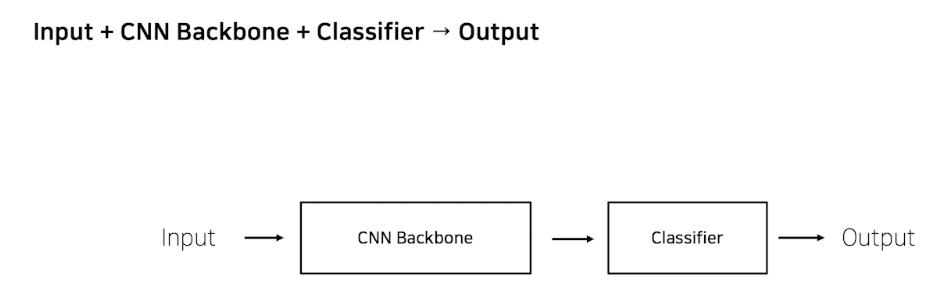
image net 사용한 모델들은 input이 image net 이고 cnn backbone은 alexnet, vgg .. etc
classifier 1000개
output
torchmodel 구조

classifier 를 1000개가 아닌 18개로 수정도 가능하고,
imagenet pretrained는 어떤 의미를 가지는지 잊지말자.
실생활의 존재하는 다양한 이미지를 1000개의 class 로 구분하자. (ex. 강아지, 고양이, 사과, 휴대폰, 의자, 화분.. 등)
구름 위성 사진

다 똑같은 구름인데, 구름 종류로 나눌때 imagenet pretrained 를 사용하는게 과연 연관이 있을까?
어떻게 다르고, 어떤 부분이 같은지를 알아야 고려하여 학습할 수 있다.
어떤 모델을 설정할 때도, 반드시 문제정의가 필요하다.
여기서도 의사결정을 위한 부분이다.
transfer learning

1) 학습 데이터가 충분히 많을 때, 그 정도에 따라 (feature 표현할 정도로 많은가?) 뭐든지 할 수 있다. 즉
1-1. 새롭게 backbone을 업데이트 할 수 있다.
우리의 task가 image net 가 비교하다면
예를 들어 사무실의 의자 책상.. 등만 10개를 비교하고 싶어.
이 경우에는 CNN BackBone은 input image의 feature을 추출하고, classifier 는 추출 embedding을 바탕으로 class에 따라 나누도록 한다.
이미 주제가 같으면 classifier 만 다시 학습하면 된다. 1000개를 10로 바꾸어 새롭게 classifier만 학습하면 된다.
$\rightarrow$ feature extraction
1-2. 반대로 유사도가 많이 떨어지면, (ex. 차 브랜드), 자동차의 어떤 feature들이 다른지에 대해 전혀 알 수 없다. image net 이 생각보다 큰 도움은 안될 수도 있지만, 그래도 학습에 도움이 될 수 있다. (경험상 완전히 과업이 imagenet이랑 달라도 imagenet 위에서 cnn backbone까지 학습을 하면 없는 것보다 수렴 속도나 결과가 더 좋다.)
$\rightarrow$ 학습 데이터가 많으면 빼봐도 되지만 웬만하면 같이 가지고 가는게 더 좋다. fine tunning
2) 학습 데이터가 충분하지 않은 경우
전체적으로 trainable 하게 만들었을 때, 반영이 어렵다. 유사도가 높으면 그냥 feature extract해서 (기존 것), classifier 만 수정해서 분류 작업 능력만 높혀서 그나마 괜찮은 결과를 얻어볼 수 있다.
유사도 까지 낮아버리면 이 경우에는 안하는게 낫다. 오버피팅, 언더피팅, 아무것도 안 될 확률도 높다.
주제를 잘 비교하고 연관성과 학습 데이터 양을 잘 고려하자.