
꺼내먹는지식 준
Matplotlib Bar Plot 본문
Bar plot(bar chart, bar graph)은 직사각형 막대로 데이터 값을 표현하는 차트 혹은 그래프이다.
범주에 따른 수치 값 비교에 적합
- 개별, 그룹 비교 모두 가능
수직 : x 축에 범주, y 축에 값 표기 (.bar())
수평 : y 축에 범주, x 축에 값 표기 (.barh())

범주가 너무 많아지면 한 화면 내에서 표현이 어렵기에, 세로 형 표현을 사용하기도 한다.
다만, 익숙한 vertical 수직을 기본으로 사용
import numpy as np
import pandas as pd
fig, axes = plt.subplots(1, 2, figsize=(12, 7))
x = list('ABCDE')
y = np.array([1, 2, 3, 4, 5])
axes[0].bar(x, y)
axes[1].barh(x, y)
plt.show()sub plot 2개 생성
subplots 함수를 사용하면 전체 subplots 을 fig 하나에 담고, 전체 낱낱개를 axes 에 담는다.
이를 통해 axes[0], axes[1]로 접근 가능, fig 는 접근 불가능 그러나 한번에 출력 가능

axes 를 통해 접근해서 형태를 결정하면, fig 에 저장된 형태도 같이 수정된다.
# 막대 그래프의 색은 다음과 같이 변경을 전체로 하거나, 개별로 할 수 있다.
# 개별로 할 때는 막대 개수와 같이 색을 리스트로 전해야 한다.
fig, axes = plt.subplots(1, 2, figsize=(12, 7))
x = list('ABCDE')
y = np.array([1, 2, 3, 4, 5])
clist = ['blue', 'gray', 'gray', 'gray', 'red']
color = 'green'
axes[0].bar(x, y, color=clist)
axes[1].barh(x, y, color=color)
plt.show()

예시
개념에 사용되는 예시
2 그룹, A,B,C,D,E 데이터
Group Sky: [1,2,3,4,5]
Group Pink: [4,3,2,5,1]
implemented code 에 사용된 예시
Student Score Dataset
1000명의 학생 데이터
feature에 대한 정보는 head(), describe(), info() 등으로 확인,
unique(), value_counts() 등으로 종류나 큰 분포 확인
Features
- 성별 : female / male
- 인종민족 : group A, B, C, D, E
- 부모님 최종 학력 : 고등학교 졸업, 전문대, 학사 학위, 석사 학위, 2년제 졸업
- 점심 : standard와 free/reduced
- 시험 예습 : none과 completed
- 수학, 읽기, 쓰기 성적 (0~100)
Student Score Dataset 간단 소개
데이터 5개 (student.sample(n) 랜덤으로 n개 뽑아보기 )
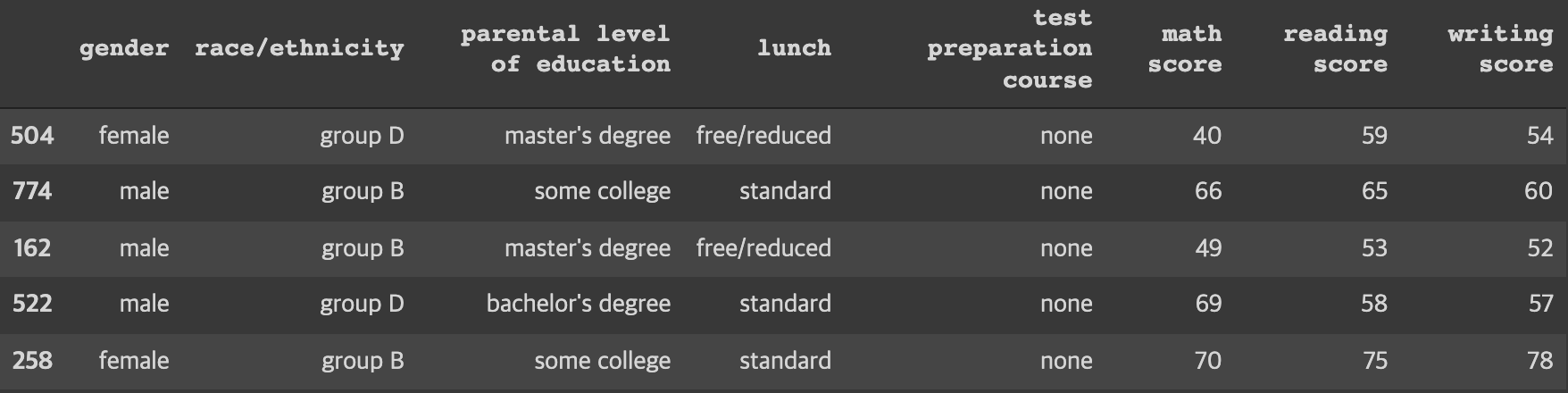
다음과 같은 features

null 값이 있는가, data_type 을 관측하여 시각화 준비
student.describe(include = 'all')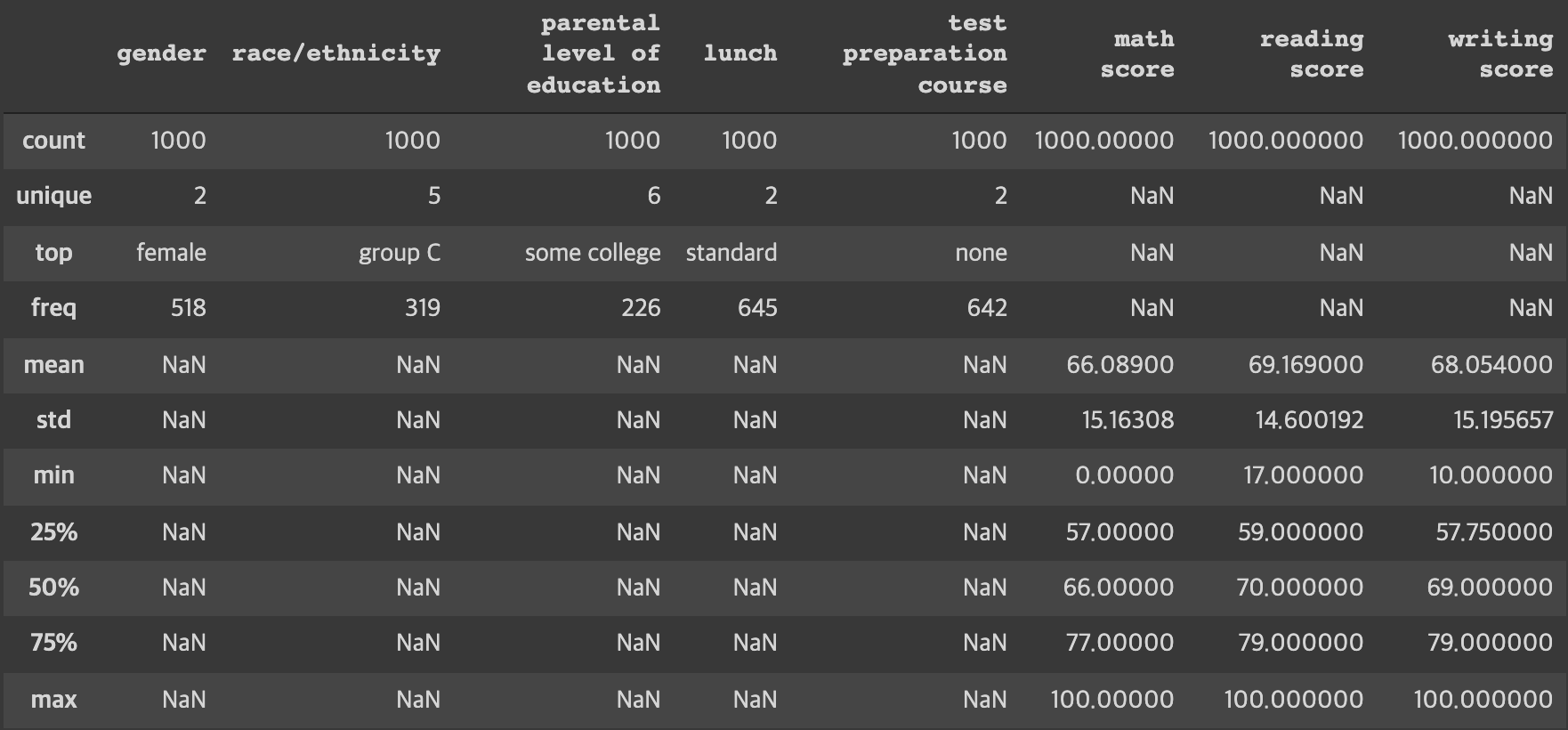
gender 2종류, race 5종류, 빈도 정보 등등 각종 정보를 빠르게 파악해볼 수 있다.
성별에 따른 인종의 분포를 파악해보자.
group = student.groupby('gender')['race/ethnicity'].value_counts()#.sort_index()
display(group)
print('-------------')
print(student['gender'].value_counts())groupby 함수는 'gender' 에 대해서 race/ethnicity 별로
value_counts() 수를 count 하는 것이다.
그냥 데이터 처리 없이, gender에 대해 value_counts() 를 하면 female, male 별 수를 count 한다.
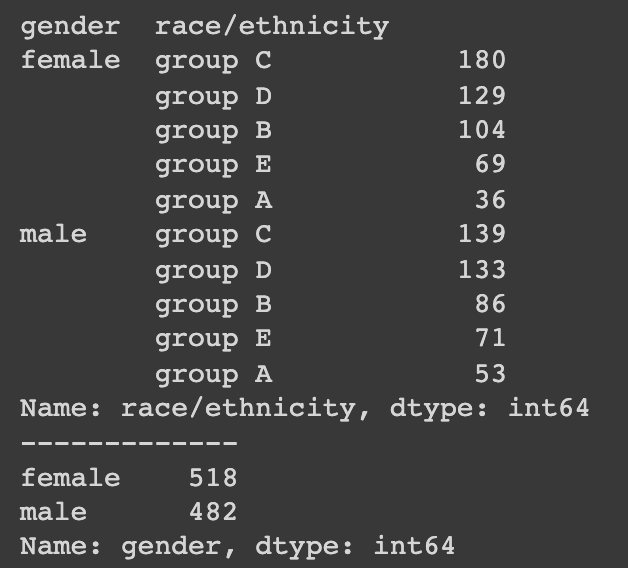
default는 value 값으로 sort 되기에, group 별로 보기 위하여 sort_index() 함수를 이용하면 A,B,C,D,E 순으로 볼 수 있다.
(이제 이 정보를 Bar Plot으로 살펴보자. )
Bar Plot
Bar Plot 은 기본적으로 1개의 feature만 보여준다.
여러 group 을 보여주기 위해서는 여러가지 방법이 필요하다.
1) 플롯을 여러개 그리는 방법 (Multiple Bar Plot)
각 그래프를 이어붙이는 방법이다.

코드 구현
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
axes[0].bar(group['male'].index, group['male'], color='royalblue')
axes[1].bar(group['female'].index, group['female'], color='tomato')
plt.show()
분포는 비슷해보이지만, 실제 수치는 차이가 있다.
matplotlib 에서 자동으로 비율에 따라 scale 을 수정한다.
따라서 Scale을 맞춰줘야 한다.
fig, axes = plt.subplots(1, 2, figsize=(15, 7), sharey=True)sharey = True 는 y축의 범위를 공유하도록 한다.

명확한 차이를 볼 수 있다.
개별적으로 y축 범위를 정해줄 수도 있다.
for ax in axes: ax.set_ylim(0, 200)개별 ax 의 y 축의 limit 을 0 - 200으로 설정해준다.

y축의 최대 최소값이 0, 200으로 고정된 것을 볼 수 있다.
2) 한개의 플롯에 동시에 나타내는 방법
- 쌓아서 표현
- 겹쳐서 투명도 조절하여 표현
- 이웃에 배치하여 표현
쌓아서 표현 (Stacked Bar Plot)

2개 이상의 그룹 쌓아서 표현
각 bar에서 나타나는 그룹의 순서는 항상 유지
맨 밑의 bar 분포는 파악하기 쉽지만, 그 외의 분포들은 파악이 어렵다.
2개의 그룹이 postive/negative 라면 축 조정 가능
.bar() 에서는 bottom 파라미터 사용
.barh()에서는 left 파라미터 사용
지금 이 차트를 보면 가장 먼저 핑크색 바가 파란 색 바보다 항상 더 큰건가? 혹은 두 바를 그냥 붙여놓은건가? 와 같은 의문점이 든다.
따라서, 이와 같은 차트를 사용할 때는 annotation 즉 주석을 필히 달아주는 것이 좋다.
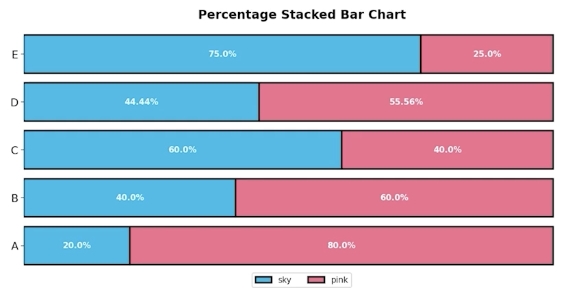
다음과 같이 각각의 범주에 대해서 percentatge 로 표현을 하여 구분을 편하게 하는 방법도 있다. 다만, 이 방법은 각 요소에 대한 총량을 비교하기는 어렵다.
코드 구현
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
group_cnt = student['race/ethnicity'].value_counts().sort_index()
axes[0].bar(group_cnt.index, group_cnt, color='darkgray')
axes[1].bar(group['male'].index, group['male'], color='royalblue')
axes[1].bar(group['female'].index, group['female'], bottom=group['male'], color='tomato')
for ax in axes:
ax.set_ylim(0, 350)
plt.show()왼쪽 그래프는 원본 데이터의 race/ethnicity 에 따른 학생 숫자 정보를 시각화 한 것이다.
동일한 형태지만, 오른 쪽 그래프는 axes[1]에 male 정보와 female 정보를 나타냈는데, bottom=group['male'] 로 bottom 을 male 데이터만큼 비우두고, 그 위에 female 데이터를 이어붙인다고 선언을 해주었다.
만약
axes[1].bar(group['male'].index, group['male'], color='royalblue')를 선언하지 않으면, 여성 그래프 아래는 비어있는다.

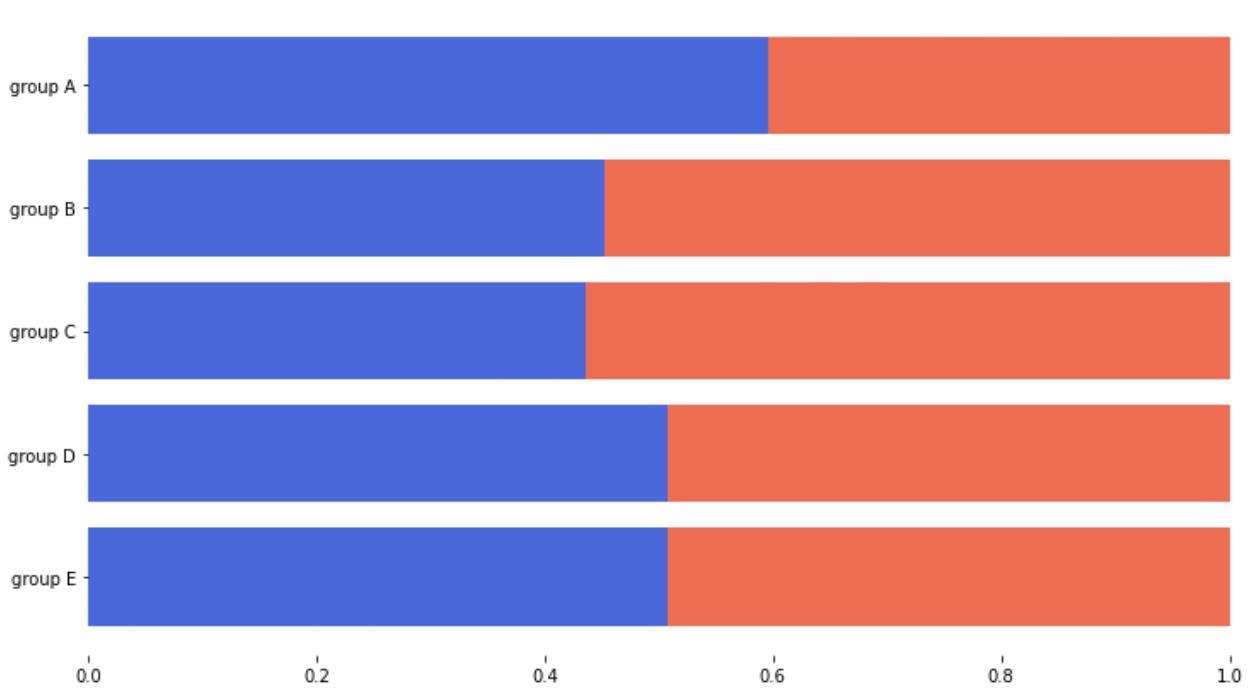
percentage stacked Bar plot
fig, ax = plt.subplots(1, 1, figsize=(12, 7))
group = group.sort_index(ascending=False) # 역순 정렬
total=group['male']+group['female'] # 각 그룹별 합
print(total)
ax.barh(group['male'].index, group['male']/total,
color='royalblue')
ax.barh(group['female'].index, group['female']/total,
left=group['male']/total,
color='tomato')
ax.set_xlim(0, 1)
for s in ['top', 'bottom', 'left', 'right']:
ax.spines[s].set_visible(False)
plt.show()subplot을 한개만 생성한다.
수평 바는 기본적으로 오름차순이 아래부터 정렬되나, 우리는 위부터 정렬되는 것에 익숙하다.
따라서 ascending = False 처리를 해주었다.
total 은 group['male'] + group['female'] 인종 그룹 별 학생의 숫자를 더한 것이다. 그냥 데이터에서 인종 group 별 index를 가져와도 된다.

별다르게 살펴봐야 할 것은, left = group['male']/total 즉, left 만큼 left 를 비운 후, female 데이터를 그렸다.
x 축의 최대 너비가 0 - 1 로, 확률 값으로 나타낼 수 있다.
spine(변), 각 변을 visible 을 False 처리하여 태두리를 없애주었다.
겹쳐서 투명도 조절하여 표현 (Overlapped Bar Plot)
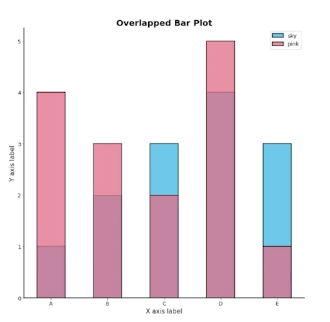
두개를 넘어가면 투명도 조절을 해도 구분이 어렵다. 따라서 3개 이상에서는 사용이 지양된다.
Bar plot 보다는 Area plot에서 더 효과적
같은 x 축과 y축을 공유하기 때문에 이전 표현 방법보다 한 눈에 알아보기 용이하다.
투명도 alpha값 외에도 실제 색상의 명도와 채도도 신경을 써야한다.
코드 구현
group = group.sort_index() # 다시 정렬
fig, axes = plt.subplots(2, 2, figsize=(12, 12))
axes = axes.flatten()
for idx, alpha in enumerate([1, 0.7, 0.5, 0.3]):
axes[idx].bar(group['male'].index, group['male'],
color='royalblue',
alpha=alpha)
axes[idx].bar(group['female'].index, group['female'],
color='tomato',
alpha=alpha)
axes[idx].set_title(f'Alpha = {alpha}')
for ax in axes:
ax.set_ylim(0, 200)
plt.show()코드를 살펴보면, 기존과 차이가 alpha 값 조절외에는 없다.
같은 ax에 male female 데이터를 그리되, 투명도를 조절하여 둘다 보이도록 한다.
alpha = 0.3 는 너무 가독성이 떨이지고, 보통 0.5 ~ 0.7을 많이 사용한다.
heuristic 하게 조정 필요.

이웃에 배치하여 표현(Grouped Bar Plt)
그룹별 범주에 따른 bar를 이웃되게 배치하는 방법
stacked bar plot에 비해 분포를 잘 볼 수 있고, overlapped 보다 가독성도 높다.
다만, matplotlib으로 구현이 비교적 까다롭다. (.set_xticks(), .set_xticklabels())

모든 방법은 그룹이 5~ 7 개 이하일 때 효과적
그룹이 많다면 적은 그룹은 ETC 처리
코드 구현
fig, ax = plt.subplots(1, 1, figsize=(12, 7))
idx = np.arange(len(group['male'].index))
width=0.35
ax.bar(idx-width/2, group['male'],
color='royalblue',
width=width)
ax.bar(idx+width/2, group['female'],
color='tomato',
width=width)
ax.set_xticks(idx)
ax.set_xticklabels(group['male'].index)
plt.show()- x축 조정
- width 조정
- xticks, xticklabels
가장 먼저 ax.bar 의 x 축이 조정된 것을 볼 수 있다. 두 bar 를 같은 곳에 그리되, x 축의 위치를 먼저 조정하고,
기존 default width = 0.7 bar를 0.35로 크기를 줄인다.
만약 width 의 크기를 줄이지 않는다면

다음과 같이 겹쳐져서 나타난다.
그 후, xticks 로 범위를 설정한 후, 범위에 따라 레이블 (xticklabels)을 설정해준다.
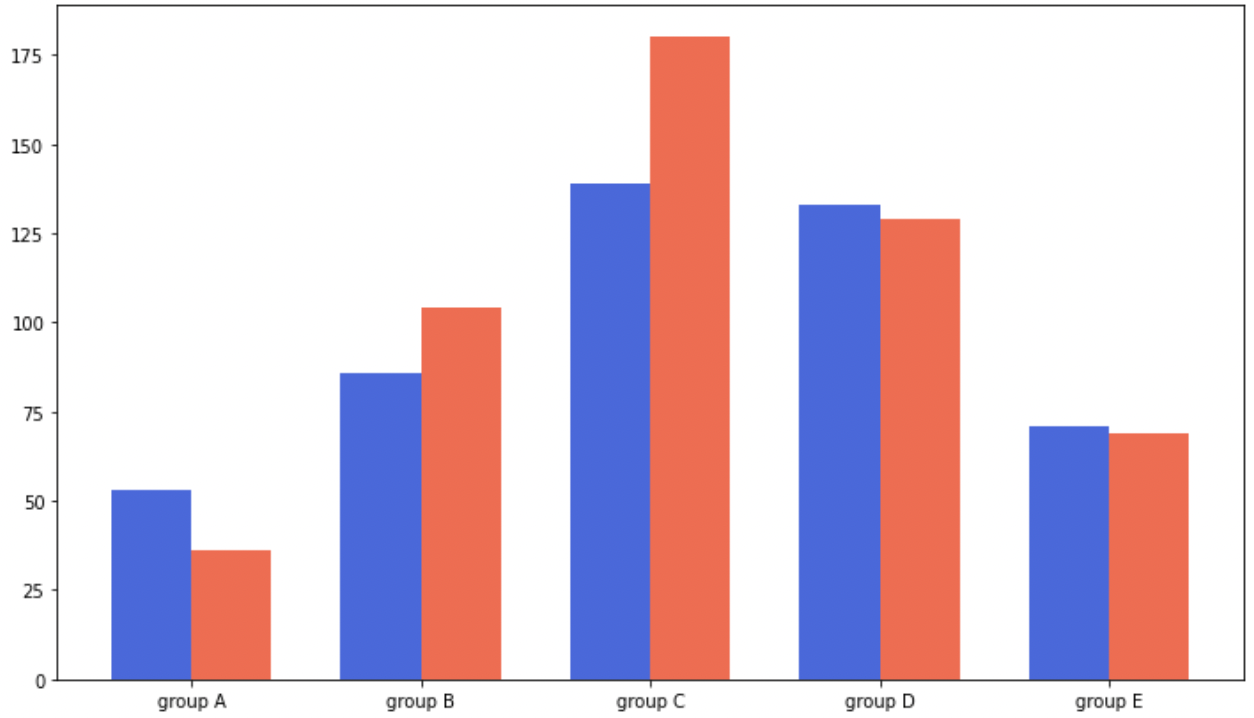
ax.bar(idx-width/2, group['male'], color='royalblue', width=width, label='Male')
ax.bar(idx+width/2, group['female'], color='tomato', width=width, label='Female')
ax.legend()
외부 정보 표기
지금이야 그룹이 2개라서 -width/2 로 구현을 했는데, 만약 그룹이 n개라면 어떻게 해야 할까?
그룹의 개수에 따라 x좌표는 다음과 같다.
- 2개 : -1/2, +1/2
- 3개 : -1, 0, +1 (-2/2, 0, +2/2)
- 4개 : -3/2, -1/2, +1/2, +3/2
규칙
$-\frac{N-1}{2}$에서 $\frac{N-1}{2}$까지 분자에 2간격으로 커지는 것이 특징이다.
그렇다면 index i(zero-index)에 대해서는 다음과 같이 x좌표를 계산할 수 있다.
\[ x + \frac{-N + 1 + 2xi}{2} \times width \]
group = student.groupby('parental level of education')['race/ethnicity'].value_counts().sort_index()
group_list = sorted(student['race/ethnicity'].unique())
edu_lv = student['parental level of education'].unique()
print(group_list)
print(edu_lv)
#['group A', 'group B', 'group C', 'group D', 'group E']
#["bachelor's degree" 'some college' "master's degree" "associate's degree"
'high school' 'some high school']
fig, ax = plt.subplots(1, 1, figsize=(13, 7))
x = np.arange(len(group_list))
width=0.12
for idx, g in enumerate(edu_lv):
ax.bar(x+(-len(edu_lv)+1+2*idx)*width/2, group[g],
width=width, label=g)
ax.set_xticks(x)
ax.set_xticklabels(group_list)
ax.legend()
plt.show()
잘 구현된 것을 볼 수 있다. 다만 곧 업로드할 seaborn에서는 더 간단하게 구현이 가능하다.
Bar Plot 원칙
Principle of Proportion Ink
- 실제 값과 값을 표현하는 그래픽의 비율이 일치해야 한다.
(100이면 100만큼 1이면 1만큼)
- x축은 0 이어야 전체적 양 비교가 용이하다.
- 막대 그래프에만 한정되는 원칙은 아니다.
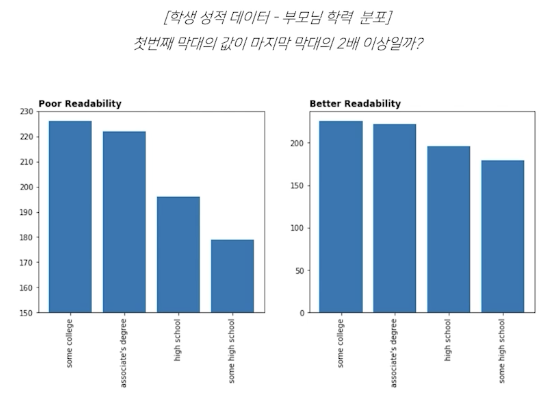
가독성은 왼쪽이 더 좋으나, 오른쪽이 정확한 정보를 전달한다.
차라리 차이를 보여주고 싶으면 플랏을 세로로 배치하고, 길이를 넓혀 차이를 보여주어야 한다.
코드 구현
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
idx = np.arange(len(score.index))
width=0.3
for ax in axes:
ax.bar(idx-width/2, score['male'],
color='royalblue',
width=width)
ax.bar(idx+width/2, score['female'],
color='tomato',
width=width)
ax.set_xticks(idx)
ax.set_xticklabels(score.index)
axes[0].set_ylim(60, 75)
plt.show()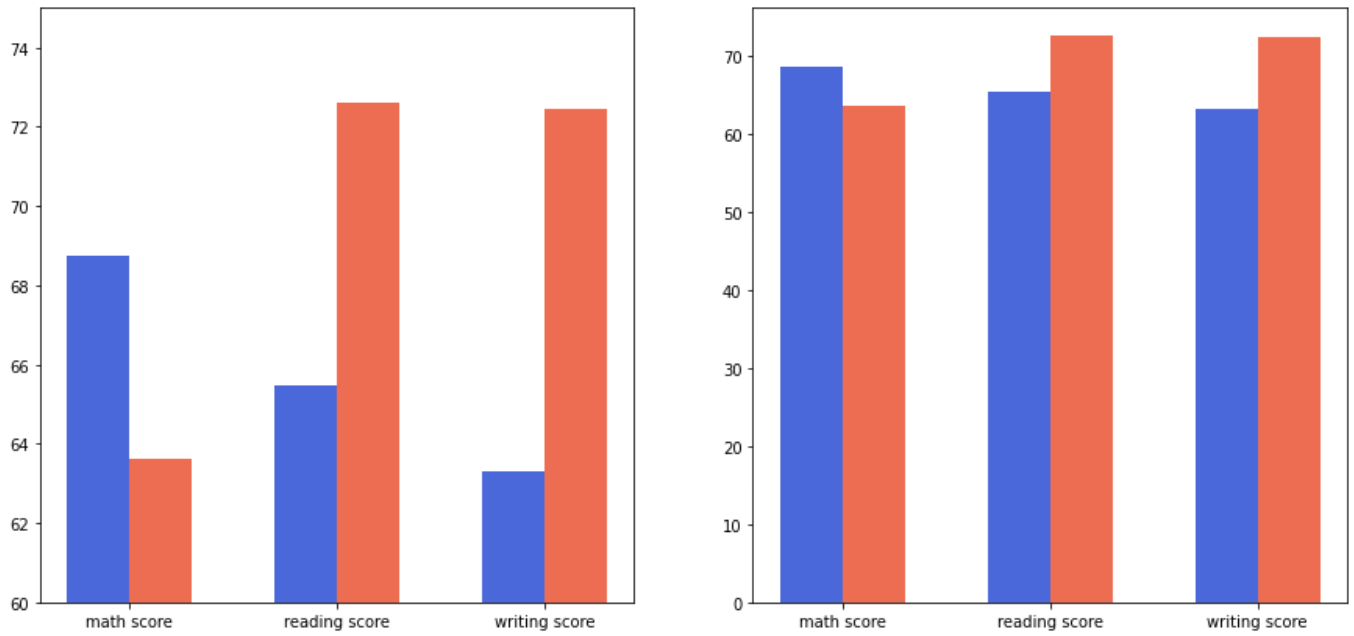
같은 값이어도 왼쪽과 오른쪽의 차이를 명확하게 볼 수 있다.
차이를 보여주고 싶으면, 다음과 같이 fig size를 변경할 수 있다.
fig, ax = plt.subplots(1, 1, figsize=(6, 10))
데이터 정렬하기
더 정확한 정보 전달을 위해 정렬이 필수
Pandas에서는 sort_values(), sort_index()를 사용하여 정렬

데이터 종류에 따라 다음 기준으로
1. 시계열 | 시간순
2. 수치형 | 크기순
3. 순서형 | 범주의 순서대로
4. 명목형 | 범주의 값 따라 정렬
대쉬보드등으로 interactive 를 제공하여 다양한 패턴을 볼 수 있도록 하면 용이하다.
적절한 공간 활용
여백과 공간만 조정해도 가독성 높아진다.
matplotlib의 bar plit은 ax가 가득 차서 살짝 가독성이 떨어진다.
matplotlib technique

Matplotlib technique
#X/Y axis Limit
.set_xlim(), set_ylim()
#Spine
.spines[spline].set_visible()
#막대 두께 Gap 0.6 0.7 추천
width
#Margins
.margins()
#legends 범례의 위치
.legen()
복잡함과 단순함
필요없는 복잡함은 필요 없다.
직사각형이 아닌 다른 형태의 bar는 지양 (3D는 알아보기 어렵다.)
3D plot을 사용하려면 최소 interactive하게 돌려보면서 잘 살펴볼 수 있도록 해야 한다.
정보에 따라
Grid, Ticklabels, Text, annote 등으로 clear 하게 전달하는 방법이 필요하다.코드 구현
- X/Y axis Limit (.set_xlim(), .set_ylime())
- Margins (.margins())
- Gap (width)
- Spines (.spines[spine].set_visible())
group_cnt = student['race/ethnicity'].value_counts().sort_index()
fig = plt.figure(figsize=(15, 7))
ax_basic = fig.add_subplot(1, 2, 1)
ax = fig.add_subplot(1, 2, 2)
ax_basic.bar(group_cnt.index, group_cnt)
ax.bar(group_cnt.index, group_cnt,
width=0.7,
edgecolor='black',
linewidth=2,
color='royalblue'
)
ax.margins(0.1, 0.1)
for s in ['top', 'right']:
ax.spines[s].set_visible(False)
plt.show()두 개의 대조군을 살펴보자.

width, edgecolor, linewidth, color 설정과 margin의 설정, 그리고 spine 즉 태두리 삭제를 통해 default와 차이를 보여주었다.
group_cnt = student['race/ethnicity'].value_counts().sort_index()
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
for ax in axes:
ax.bar(group_cnt.index, group_cnt,
width=0.7,
edgecolor='black',
linewidth=2,
color='royalblue',
zorder=10
)
ax.margins(0.1, 0.1)
for s in ['top', 'right']:
ax.spines[s].set_visible(False)
axes[1].grid(zorder=0)
for idx, value in zip(group_cnt.index, group_cnt):
axes[1].text(idx, value+5, s=value,
ha='center',
fontweight='bold'
)
plt.show()
*zorder 그림이 그려지는 깊이, grid 를 차트 위에 그릴 수도 있다.
*zip: 함수는 여러 개의 순회 가능한(iterable) 객체를 인자로 받고, 각 객체가 담고 있는 원소를 터플의 형태로 차례로 접근할 수 있는 반복자(iterator)를 반환
grid 형성, x = idx y= value보다 5칸 위에, s = value 즉 텍스트는 value, ha = 'center ' 작성 위치 center, fontweight = bold.
ETC
오차 막대 추가로 Uncertainty 정보를 추가 가능
Bar 사이 Gap 이 0이라면 히스토그램
.hist()
연속적 느낌 제공 가능
다양한 Text 정보 활용
.set_title()
.set_xlabel(), _ylabels()
코드 구현
score_var = student.groupby('gender').std().T
score_var
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
idx = np.arange(len(score.index))
width=0.3
ax.bar(idx-width/2, score['male'],
color='royalblue',
width=width,
label='Male',
yerr=score_var['male'],
capsize=10
)
ax.bar(idx+width/2, score['female'],
color='tomato',
width=width,
label='Female',
yerr=score_var['female'],
capsize=10
)
ax.set_xticks(idx)
ax.set_xticklabels(score.index)
ax.set_ylim(0, 100)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.legend()
ax.set_title('Gender / Score', fontsize=20)
ax.set_xlabel('Subject', fontweight='bold')
ax.set_ylabel('Score', fontweight='bold')
plt.show()yerr 은 에러바
capsize 는 단지 표기 방법
21. Matplotlib 에러바 표시하기
 **에러바 (Errorbar, 오차막대)**는 **데이터의 ...
wikidocs.net

'CS > 데이터시각화' 카테고리의 다른 글
| Matplotlib 기본기에서 벗어나는 몇가지 팁 (0) | 2022.02.07 |
|---|---|
| Matplotlib Scatter Plot (0) | 2022.02.04 |
| Matplotlib Line Plot (0) | 2022.02.03 |
| Matplotlib 기본 (0) | 2022.02.03 |
| 데이터 시각화란? (0) | 2022.02.03 |



