
꺼내먹는지식 준
머신러닝 정리 4.5(2) - 앙상블이란?, Random Forests 본문
앙상블
앙상블에 대한 General하고 Naive한 정의는 여러 약한 알고리즘의 힘을 합쳐서 하나의 강력한 의사결정을 하는 머신러닝 기법이다.
앙상블은 배깅, 부스팅, 보팅으로 나뉜다.
- 배깅 : 동일 알고리즘의 약 분류기를 병렬로 사용
- 부스팅 : 동일 알고리즘의 약 분류기를 직렬로 사용
- 보팅 : 다른 알고리즘의 약 분류기를 병렬로 사용
(분류기가 아니라 회귀문제일 수도 있다.)
분류문제에 입각하여 앙상블을 정의해보면 다음과 같다.
앙상블은 여러 개의 의사 결정 트리(Decision Tree)를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝 기법이다.
즉, 여러 개의 약 분류기(Weak Classifier)를 병렬 또는 직렬로 결합하여 강 분류기(Strong Classifier)로 만드는 것이다.
배깅(Bagging)

- 원본 데이터를 랜덤 샘플링(복원 추출)해, 크기가 동일한 n개의 샘플 데이터를 생성한다. 이 과정을 Bootstrapping이라 한다.
- 각 샘플 데이터를 기반으로 동일한 알고리즘 기반의 의사 결정 트리를 병렬적으로 학습한 뒤,
- 각 모델의 학습 결과를 결합하는 방식이다.
- 일반적으로 학습 결과를 결합할 때,
- 회귀 문제라면 평균(average),
- 분류 문제라면 다중 투표(majority vote)가 사용된다.
- 대표적인 배깅 모델로는 'Random Forest'가 있다.
Random Forest
랜덤 포레스트는 배깅의 일종이므로, 먼저 Bootstrapping을 수행한다.
- 원본 데이터를 랜덤 샘플링(복원 추출)해, 크기가 동일한 n개의 샘플 데이터를 생성한다. 이 과정을 Bootstrapping이라 한다.
약 분류기인 Decision Tree 를 생성하는 과정이 모델의 핵심 포인트이다.
기존 Decision Tree와 달리 모든 feature를 Tree 생성에 사용하지 않는다.
예를들어 feature이 약 30개 주어진다하면, Information Gain의 결과(거의 이것 때문) + Prunning 과정으로 인해 몇개의 강력한 feature만이 데이터를 분류하는데 적극적으로 활용된다.
강력한 feature외의 feature 들은 의사결정 과정에 직접적으로 거의 기여가 없게 된다.
이를 해결하기 위하여 각각의 약 분류기를 생성할 때 사용할 feature의 개수를 지정해놓고 feature를 random sampling하여 각각 다른 feature를 고려한 여러 약 분류기의 tree를 생성하여 의사결정 과정에 참여하도록 한다. (투표로 결정한다.)
여기까지가 Random Forest 개념의 골자였다면, 아래는 추가적인 사항이다.
- 흥미로운 점은 Bootstrapping 을 통해 각 tree의 학습 데이터셋을 만들게 되면 각각 random sampling과정에서 놓치게 되는 data가 존재하게 된다. 이를 Out of Bag Samples라 한다. Out of Bag samples은 tree 학습 과정에서 관측하지 못한 데이터이므로, 성능 점검에 적극적으로 활용할 수 있다. 또한 tree 들이 약간씩 다른 데이터셋으로 학습했다는 점에서 Overfitting도 어느정도 피하도록 돕는다.
- Out of Bag Samples로 Accuracy를 비교한다. 이후 가장 성능이 좋은 feature의 개수를 선택하기 위해 feature의 개수를 조정해가며 Out of Bag error가 가장 낮은 상황을 찾는다.
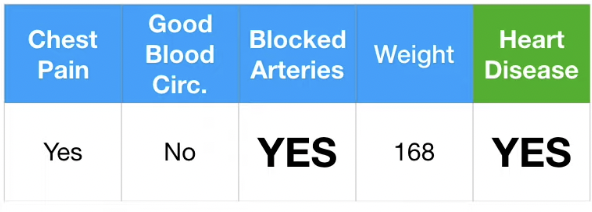
- 결측치가 존재하는 경우
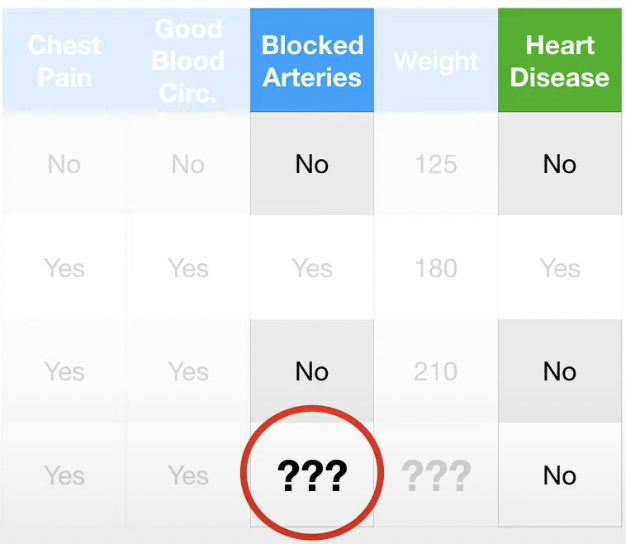
위와 같이 Blocked Arteries, Weight 의 데이터가 결측된 결과표가 있다고 가정하자.
기본적으로 Random Forests는 결측치가 존재할 때, Weak Guess 를 한 후, Guess 를 강화하는 방식으로 접근한다.
첫 Guess는 Label 값을 기준으로, 동일 label을 가진 다른 데이터를 참고한다.
이에 따라 Blocked Arteries 는 "No", Weight 는 (125+210)/2 = 167.5로 Guess 한다.
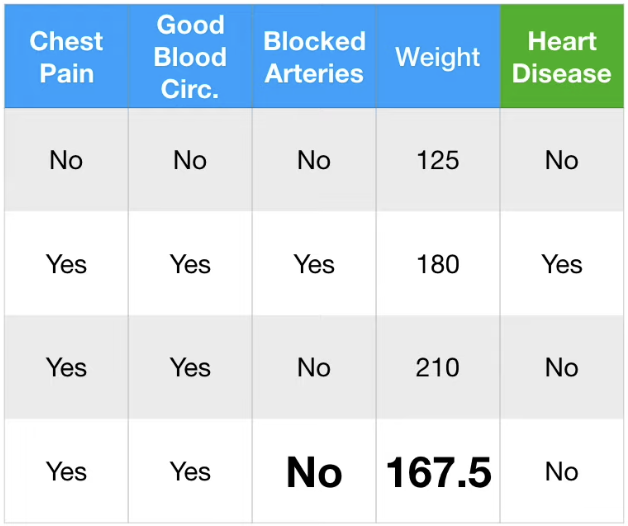
Guess 를 Refine 하여 더 강력한 Guess 를 만들어보자.
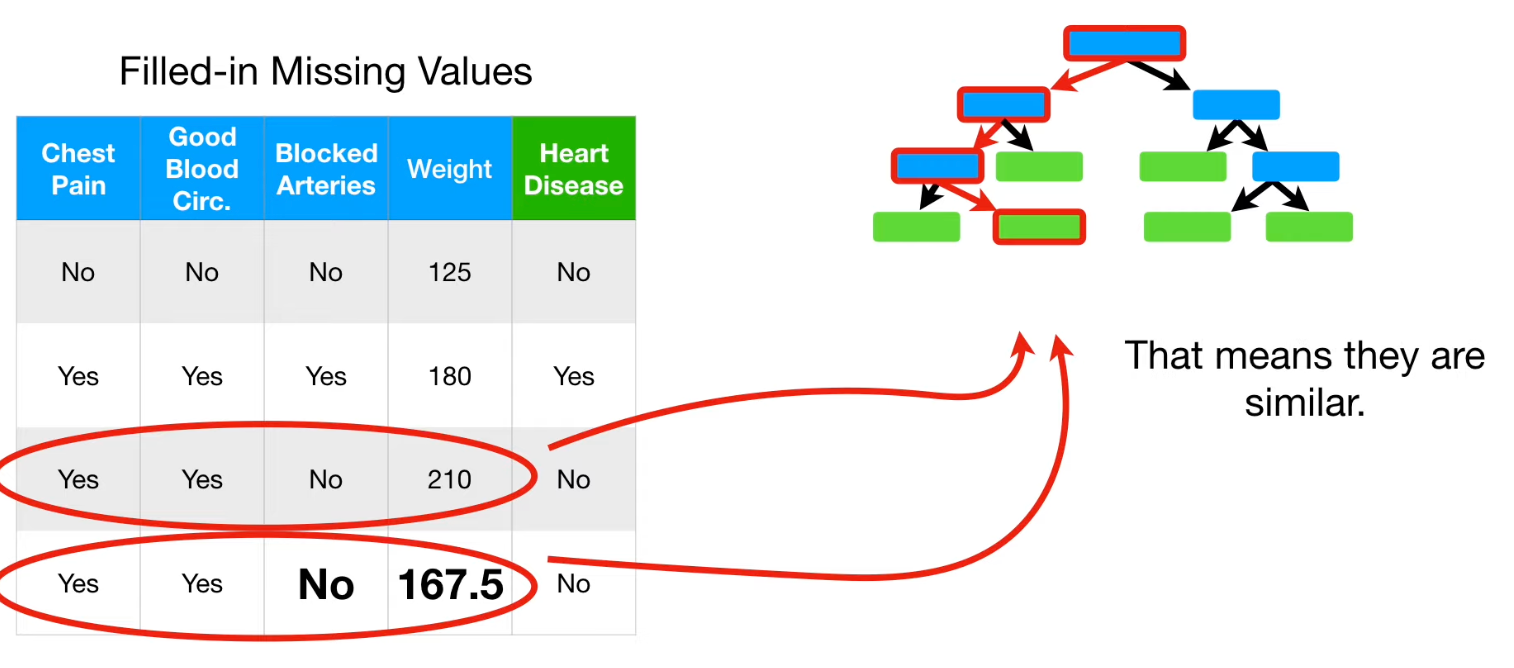
Decision Tree로 분류한 결과 같은 leaf 노드에 떨어지는 데이터는 유사하다고 할 수 있다.
이러한 정보를 활용하여 Proximity Matrix 를 만들 수 있다.
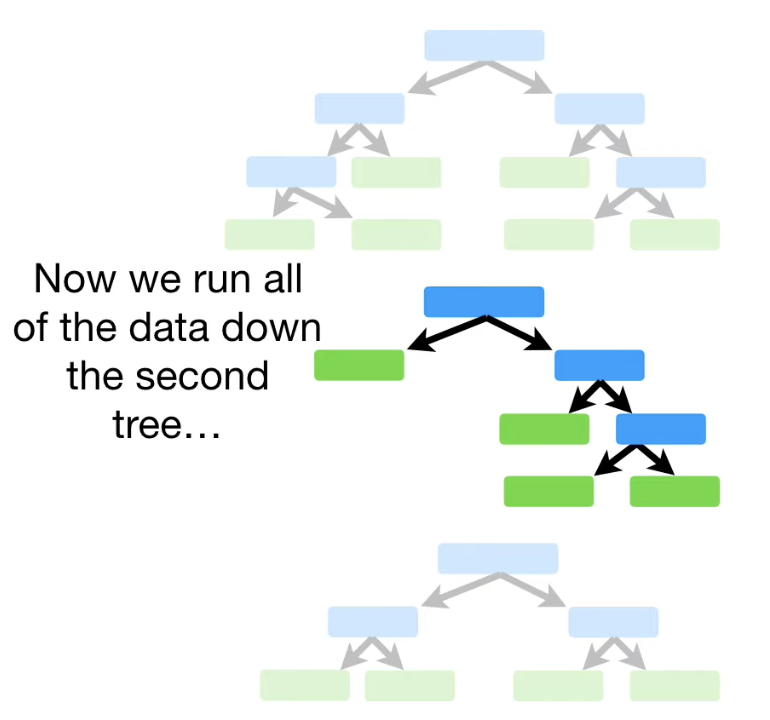
데이터를 모든 Tree에 넣고 돌려보면서 나온 결과들을 matrix에 기입한다.
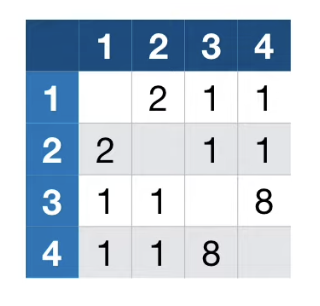
그 결과 다음과 같은 Proximity Matrix 를 얻을 수 있다.
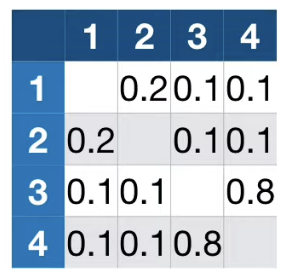
Proximity Matrix를 Tree의 총 개수로 나누어 준다. (만약 모든 tree에서 동일한 결과를 얻은 두 데이터라면 matrix에는 1이 기입되게 된다.)
이제 이 정보를 활용하여 4번 데이터의 결측치를 업데이트 해보자.
4번 데이터는 1번 데이터와 0.1 , 2번 데이터와 0.1, 3번 데이터와 0.8의 관계가 있다.

결측치 Bolcked Arteries 에 대해 2번 데이터는 "YES"라 응답한다.
"YES" 는 3번 중 1번 등장했으므로, $\frac{1}{3}$ 이라 할 수 있다.
"YES" 의 weight는 $\frac{\textrm{2번 데이터의 proximity 값}}{\textrm{4번 데이터의 전체 proximity 합}}$ 으로 구할 수 있다.
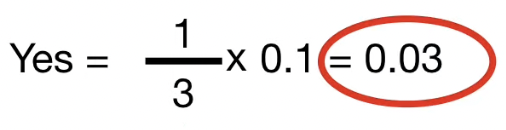
결과는 위와 같이 나타난다.
동일한 방법으로 "NO"의 weight를 구하면 아래와 같고,
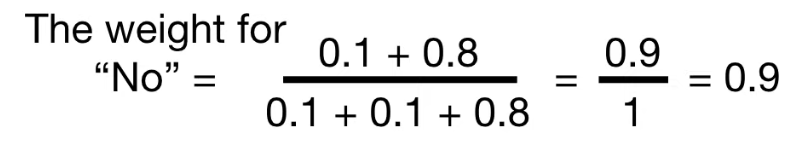
그 결과 NO 에 해당되는 cetainty 값은 0.6임을 알 수 있다.
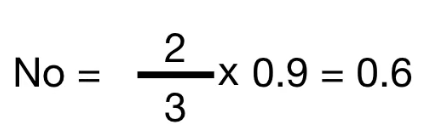
이를 통해 4번 데이터의 Blocked Arteries 결측치는 "NO" 가 유지된다.
동일한 방법으로 Weight 결측치도 살펴보자.
continuous 한 값이니, 각 값에 weight 를 바로 곱해서 더해주면 된다.
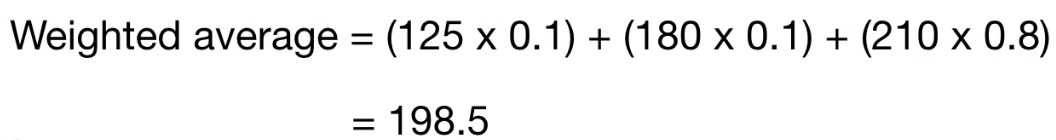
이를 통해 4번 데이터의 Weight 결측치를 198.5로 업데이트한다.
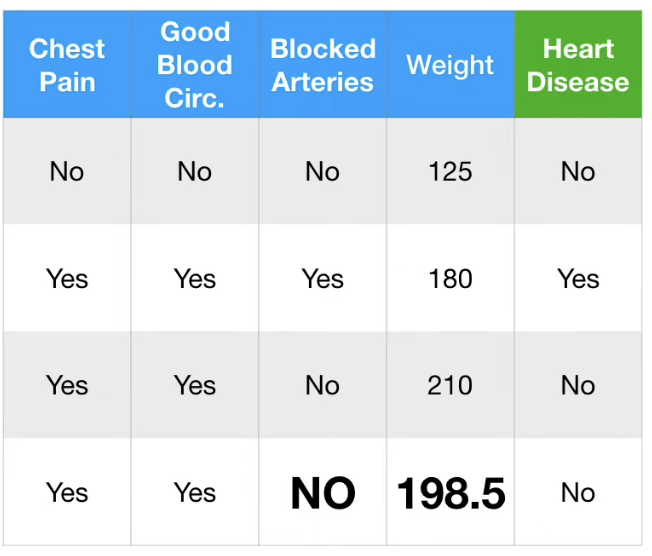
이 과정을 몇번 반복하면 (5~6번), 각 결측치가 특정 값에 수렴하게 된다.
proximity matrix 는 활용도가 높다.
예를 들어 아래와 같은 proximity matrix 가 있다고 가정해보자.
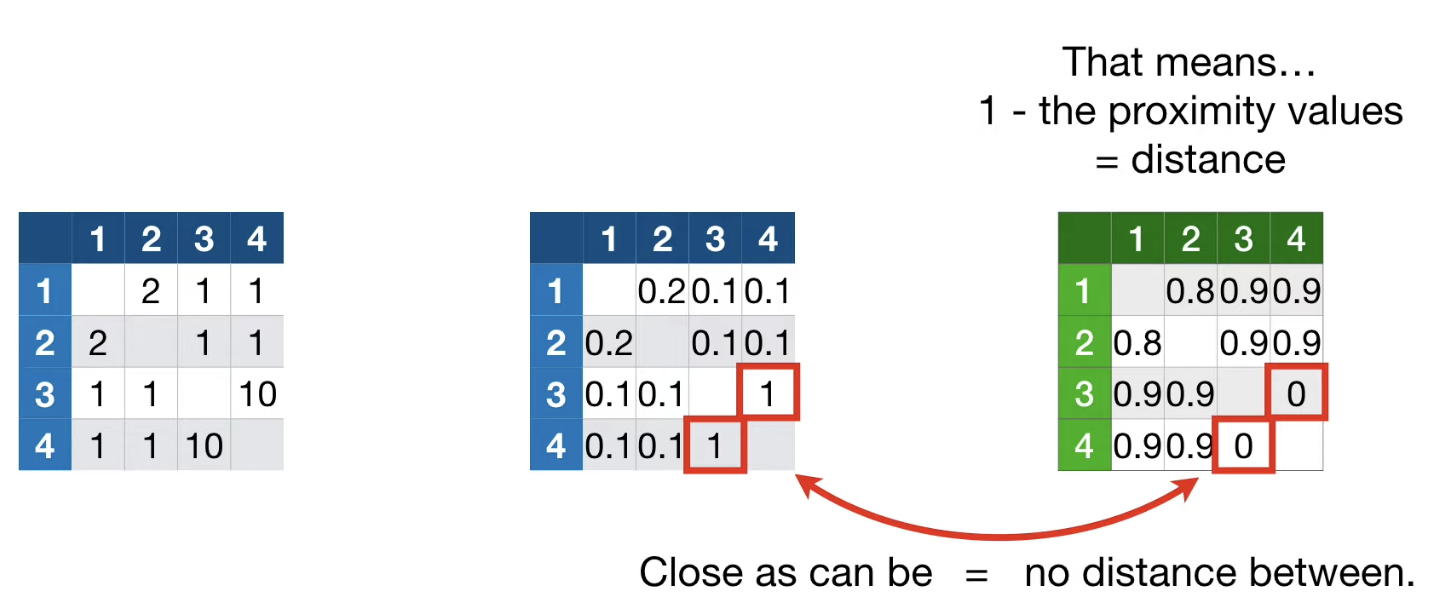
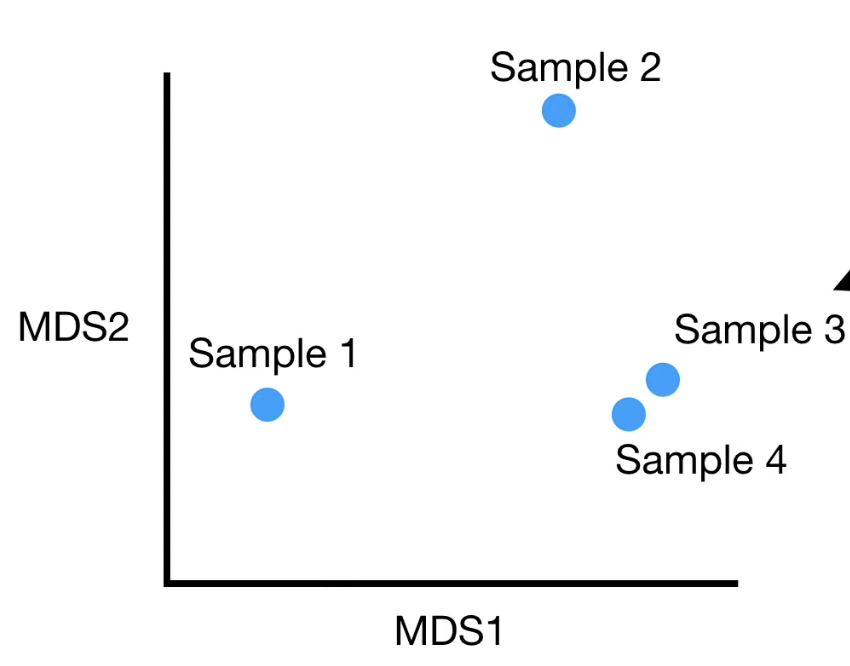
1 - proximity values 의 결과 값을 각 데이터 샘플 간의 distance 라고 볼 수 있다.
이를 통해 히트맵이나 MDS plot 을 만들 수 있다. 즉, 샘플 들 간의 관계를 시각화하는 것이 간단하다.

trainig dataset이 아닌 input data에 결측치가 존재한다면 어떡해야 할까?
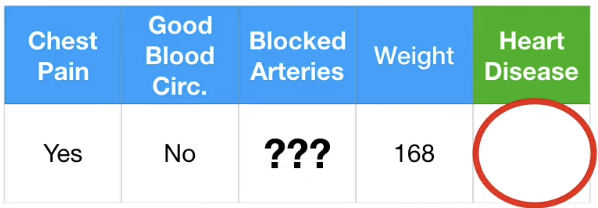
해당 환자는 Heart Disease 가 있을까 없을까?
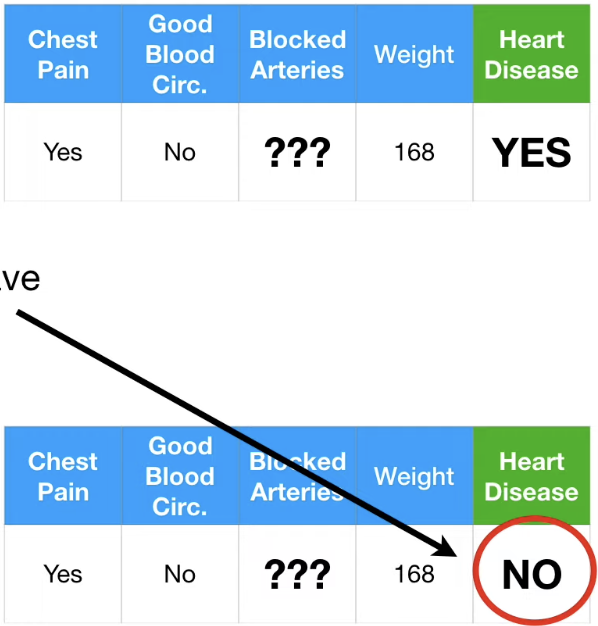
먼저 두가지 경우를 모두 가정해보자.
이 후 iterate 과정을 통해 각각의 Blocked Arteries 를 채워보면 아래와 같이 된다.
그리고 그 결과를 통해 얻은 데이터 샘플들을 tree에 넣어보자.
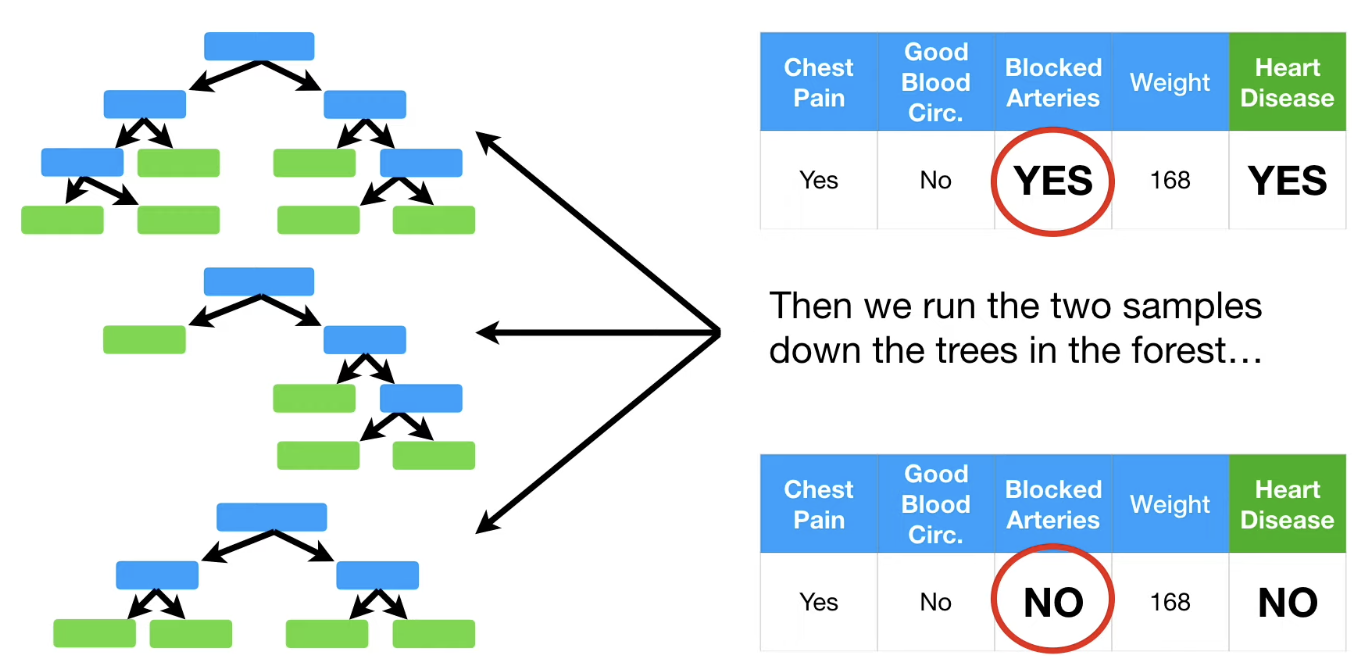
각각의 데이터 샘플을 tree에 돌린 결과 label 이 옳게 나온 경우는 각각
Blocked Arterires "YES", Heart Disease "Yes" : 3번
Blocked Arterires "NO", Heart Disease "NO" : 1번 으로 3번이 더 많이 나왔다.
즉 최종 결과는 아래의 데이터 샘플을 선택한다.
Random Forest 는 결측지에도 강하고, Overfitting 에도 강한, 그리고 시각화도 가능한 강력한 머신러닝 Bagging 기법이다.
'AI > 머신러닝' 카테고리의 다른 글
| 머신러닝 정리 4.5(3) - AdaBoost (1) | 2023.02.16 |
|---|---|
| 머신러닝 정리 4.5 -회귀 나무 (Regression Tree) (0) | 2023.02.15 |
| 머신러닝 정리 9 - Naive Bayes vs Logistic Regression (0) | 2022.11.02 |
| 머신러닝 정리 8.5(2) - Naive Bayes는 Generative Model (0) | 2022.11.01 |
| 머신러닝 정리 8.5(1) - Discriminative model vs Generative Model (2) | 2022.10.31 |



