
꺼내먹는지식 준
MMdetection 사용법 간략 설명 본문
MMdetection 사용법에 대한 간략한 설명
MMdetection은 config 파일의 parameter를 수정하는 것만으로도 여러가지 detection 을 수행할 수 있도록 하는 강력하고 쉬운 도구입니다. 다만, 워낙 내부의 구조를 감춰놓다보니 config 의 parameter가 무엇이 있는지, 어떻게 사용하는지에 대한 선행 숙지가 필수입니다.
구성은 다음과 같습니다.
- Model config: model 의 architecture
- Dataset config: 어떤 데이터 셋을 불러올 것인가, dataset Augmentation
- Scheduler config: Optimizer, Learning rate scheduler
- Runtime config: 모델 성능 무관, log 찍는 방식 관련

Object Detection 모델의 형태는 다음과 같습니다.

- Input 이 들어오면 Backbone이 각 stage별로 feature map을 뽑습는다.
- Neck에서는 각 뽑힌 feature map의 결합이 일어나고,
- Head로 넘어가서 prediction을 수행합니다.
- Two stage의 경우 Dense prediction이 region proposal 역할을 하고, sparse prediction에서 prediction을 합니다.
Model Config
One Stage Config 구조
1. type:
어떤 detector를 사용하는가를 결정합니다.

2.backbone

backbone마다 필요로 하는 parameter(변수)가 다릅니다.
이에 따라 각 backbone에서 필요로 하는 parameter를 먼저 숙지하면 좋습니다.
여기서는 공통적으로 사용 많이 되는 parameter만 소개합니다.
- type: 어떤 backbone model을 사용할지를 의미합니다.
- num_stages: (backbone) 총 몇개의 stage에서 feature map 을 뽑아낼 것인가를 의미합니다.
- out_indicies: 몇번째 stage에서 feature map을 추출 할 것인가입니다. 이 또한 모델마다 뽑아내는 feature map 의 위치가 다르므로 꼭 숙지해야 하는 부분입니다.
3. neck

- type: 어떤 neck을 사용할지를 의미합니다.
- in_channels = backbone에서 stage별로 추출한 feature map의 각 channel 크기 입니다.
- out_channels = neck에서 feature를 결합한 후 최종 head 로 넘겨주기 전 단계의 channel 크기 입니다.
4. bbox_head
prediction 을 수행합니다.

type: 사용할 Head type 을 명시합니다.
num_classes: dataset의 label 의 개수에 따라 결정됩니다. 현재는 coco dataset 기준으로 80개입니다.
in_channels: neck 부분에서 넘겨준 channel의 크기입니다.
stacked_covs: Head 부분에서 Convolution을 생성해서 마지막 prediction을 수행합니다. 이때 사용하는 convolution의 총 개수입니다. 아래 그림에서는 stacked_convs가 3 인 것을 확인할 수 있습니다.

anchor_generator:

bbox_coder:

loss_cls
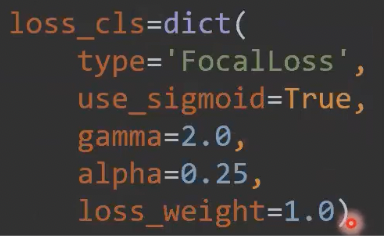
los_bbox

5. train_cfg
모델 학습시 사용하는 parameters
- pos_iou_thr : positive label 판단 기준
- neg_iou_thr : negative label 판단 기준
- min_pos_iou : 박스 크기가 특정 크기보다 작은 경우 무시합니다.

6. test_cfg
test 시에는 post processing이 진행되기에 , nms type 을 넣어주는 것 등입니다.
만약 test 기준이 mAP = 0.7 이면 iou_threshold=0.7로 post processing을 하는 것이 좋습니다.

Two Stage Config 구조
One stage에서 추가된 부분만 서술합니다.
rpn_head


in_channels: neck에서 나오는 feature 의 channel을 받아줍니다.
roi_head

roi 추출 방법에 대해서 config의 작성입니다.
Dataset Config

1. samples_per_gpu
: 1개의 gpu에 몇개의 이미지를 올릴 것인지 결정합니다. , 즉 single gpu 기준 batch size 입니다.
2. workers_per_gpu
: gpu worker 개수
3. train
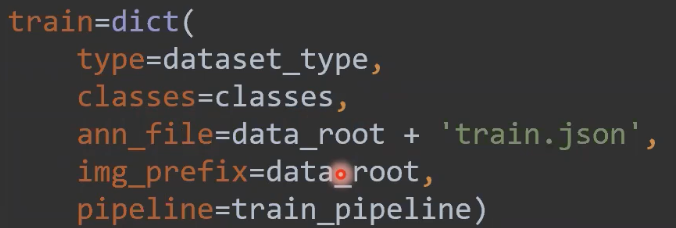

클래스에서는 UNKNOWN을 제거하고 작성하셔야합니다.
ann_file은 json 파일 경로를 작성해주시면 됩니다.
img_prefix는 이미지들이 어디에 있는지 작성하면 됩니다.
pipeline

굉장히 중요한 부분입니다.
Transform에 대한 정보가 여기에 작성이 됩니다.
4. val
5. test

이 부분은 TTA 부분입니다.
Scheduler
크게 optimizer와 Learning Rate Scheduler를 갖습니다.

optimizer_config 는 grad_clip 이 들어갑니다. 학습하다가 loss 가 None이 뜨거나 오류가 발생하곤 하는데, 이경우 LR 을 낮추거나 clip을 걸어줍니다.
Learning Rate config도 작성할 수 있습니다.