
꺼내먹는지식 준
Pytorch 차원 (dim, axis) 본문
pytorch 에서 함수 사용할 때 마다 인자로 dim 을 줄 때 차원이 햇갈렸다.
이에 따라 간략 정리 한번 한다.
(일단 axis 와 dim 은 같다는걸 인지하고 시작하자.)
2D, 3D, 4D 에서 torch.cat 을 수행하며 차원에 따른 concat 결과를 명확하게 봐보자.
a = torch.randn(7,3)
b = torch.randn(7,3)
print(torch.cat((a,b),axis=0).shape)
print(torch.cat((a,b),axis=1).shape)
a = torch.randn(7,3,5)
b = torch.randn(7,3,5)
print(torch.cat((a,b),axis=0).shape)
print(torch.cat((a,b),axis=1).shape)
print(torch.cat((a,b),axis=2).shape)
a = torch.randn(7,3,5,4)
b = torch.randn(7,3,5,4)
print(torch.cat((a,b),axis=0).shape)
print(torch.cat((a,b),axis=1).shape)
print(torch.cat((a,b),axis=2).shape)
print(torch.cat((a,b),axis=3).shape)torch.cat 의 결과


다음의 결과를 통해 axis(dim) = 0 은 가장 앞의 축임을 알 수 있다.
axis(dim) = 1 은 말그대로 2번째,
axis(dim) = 2 는 말그대로 3번째,
2D list, lst[y][x]가 주어졌을 때 indexing 과정속에서 x 가 0번째 축이라 종종 착각한다.
그러다보니 자꾸 dim = 0 이 x 축일거란 착각을 한다.
x축은 주어진 차원에서 마지막 축
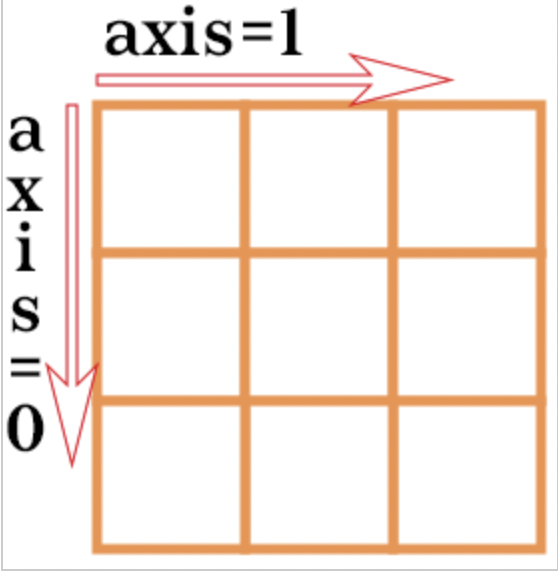
이번 기회에 딱 정리했다.
print(torch.cat((a,b),axis=0))
tensor([[ 1.2917, 0.2620, 0.6202],
[ 0.0505, -0.4551, -0.6541],
[-0.2203, 0.5465, -0.4095],
[-1.0510, -0.5619, 1.8798],
[-2.1109, -0.4136, -1.4428],
[-0.8506, 1.5815, 1.1198],
[-0.3152, -0.2572, 1.3402],
[ 1.0722, -0.2650, 0.4702],
[-1.9085, -0.4661, -1.3931],
[ 1.0777, 1.0078, 0.6271],
[-0.4740, -1.2951, -1.1841],
[-0.7953, 0.6182, -2.8724],
[-0.0247, -1.0597, -0.3441],
[-1.8260, 1.8262, -0.2412]])
추가 내용
a = torch.randn(2,3,2,4)
a = F.softmax(a, dim=2)
print(a.shape)
print(a)
b = a[:, :, :, 1].contiguous()
print(b.shape) # 2,3,2
print(b)
---------------------------------------------------------------------
#아래는 출력
torch.Size([2, 3, 2, 4])
tensor([[[[0.2449, 0.3229, 0.3774, 0.8142],
[0.7551, 0.6771, 0.6226, 0.1858]],
[[0.7050, 0.5942, 0.4972, 0.3467],
[0.2950, 0.4058, 0.5028, 0.6533]],
[[0.5513, 0.4419, 0.3673, 0.5437],
[0.4487, 0.5581, 0.6327, 0.4563]]],
[[[0.2380, 0.3532, 0.5484, 0.6704],
[0.7620, 0.6468, 0.4516, 0.3296]],
[[0.7316, 0.2871, 0.9310, 0.4289],
[0.2684, 0.7129, 0.0690, 0.5711]],
[[0.2533, 0.5014, 0.6543, 0.3208],
[0.7467, 0.4986, 0.3457, 0.6792]]]])
torch.Size([2, 3, 2])
tensor([[[0.3229, 0.6771],
[0.5942, 0.4058],
[0.4419, 0.5581]],
[[0.3532, 0.6468],
[0.2871, 0.7129],
[0.5014, 0.4986]]])
[:, :, :, 1]
2 X 3 X 2 X 4 $\rightarrow$ 2 X 3 X 2
모든 원소 3차원에서는 첫번째 원소만 가져와서 2 X 3 X 2 생성
직접 indexing 하므로 해당 차원 소멸
tmp[start:end:step]
tmp = torch.randn(3,12)
tmp[:,::2]
#all 3 from axis = 0, every 2nd element in the axis = 1
차원이 달라도 덧셈이 가능한 경우
차원이 달라도 다른 차원 중 한 쪽의 크기가 1이면 가능
(1,4,3) + (3,1,3)
(1,9,3,1) + (89,1,1,3219) 다 가능하다.
>>> a
tensor([[ 0.4471, -0.3994],
[ 0.2245, 0.0233],
[-1.2502, 1.0926]])
>>> b
tensor([[ 1.3985, -1.0290]])
>>> a+b
tensor([[ 1.8456, -1.4284],
[ 1.6230, -1.0057],
[ 0.1484, 0.0636]])
※편리한 indexing 기법
2D array의 경우 순서쌍으로도 indexing 하는 것이 가능하다.
list, np.array, tuple 형태에 상관 없이 가능
당연히 indexing 을 위한 두 array의 크기는 같아야한다.
하지만 아래와 같이 아예 원소 자체를 순서쌍으로 직접 접근하려는 건 동작하지 않는다.
a = np.arange(40).reshape(5,8)
print("list: ", a[[1,2,3], [1,2,3]])
print("np.array: ", a[np.array([1,2,3]), np.array([1,2,3])])
print("tuple: ", a[tuple([1,2,3]), tuple([1,2,3])])
'''
list: [ 9 18 27]
np.array: [ 9 18 27]
tuple: [ 9 18 27]
'''
#print("list: ", a[[1,2],[2,2], [3,1]])
#print("np.array: ", a[np.array([1,2],[2,2], [3,1])])
print("tuple: ", a[ tuple([1,2]),tuple([2,2]), tuple([3,1]) ])
IndexError: too many indices for array: array is 2-dimensional, but 3 were indexed
https://blog.naver.com/ha_junv/222220449023
Numpy 사용법 총정리
Numpy는 AI 연구를 하고자 하는 연구자라면 당연히 다룰 줄 알아햐 나는 기본 Library이다. 그러나 사...
blog.naver.com
한창 네이버 블로그를 하던 필자가 작성했던 글
a[:][1] != a[:,1]
[:,1] 는 각 row에 접근하여 해당 element를 가져오는 것이었다면, [:][1]는 기본적으로 전체 row를 반환하고, 그 중 2번째 row를 반환해라로 읽는다. 여기서 또 햇갈릴 수 있는 부분이 있다. 다음의 예제를 보자.
a = np.zeros((10,4))
b = [True, False, True, False, True, True, False, False, False, True]
a[b][2][3] = 1
print(a[b][2][3])
print(a[b][2])0.0
[0. 0. 0. 0.]a[b][2][3] = 1 을하면 적어도 a[b][2][3] 은 1로출력될 것 같으나 그렇지 않다. 다음은 index를 접근하는 개념이 아니라 반환하는 개념이라 복사가 되서 그런 것으로 보인다.
