
꺼내먹는지식 준
Conditional Gan 구현 본문
논문이 굉장히 짧으니 한번 읽어보는 것 추천
노이즈로부터 생성한 가짜 결과물인 z와, 진짜 결과물 x만 가지고 티키타카를 했었던 기존 GAN과는 condition 을 제공한다.
GAN 의 목적 함수
$\textrm{min}_G \textrm{max}_D V(D,G)=E_{x∼p_{data(x)}}[\log D(x)]+E_{z∼p_{z(z)}}[\log (1−D(G(z))]$
$x∼p_{data(x)}$: 실제 데이터의 분포
$z∼p_{z(z)}$: 분포가정(ex. 정규분포)에서 온 latent code의 분포
GAN의 판별자 D는 real or fake를 판단하기 때문에, Binary Cross Entropy(이하BCE)를 사용함. real일 때 y = 1, fake일 때 y = 0
판별자 G는 random noise z가 condition 과 같이 들어왔을 때, G 분포에서 condition 값(GT)과 가장 가까운 값을 뽑아낸다.
논문의 골자
기존 Gan 에서 condition 하나 추가 된 것.
하단의 모델 아키텍쳐를 보면 condition으로 y 가 제공되는 것 확인 가능

Unconditional 생성모델에서, 데이터가 생성되는 종류(mode)를 제어할 방법은 없다. 그러나, 추가 condition을 통해 데이터 생성 과정을 제어할 수 있다. 이러한 조건 설정(conditioning)은 class label 등에 기반할 수 있다.
$\rightarrow$ 이로 인해 Discriminator가 같은 데이터만보고 스스로 잘하는줄 착각하는 오류 방지
코드
논문을 보고 구현할라고 치면 굉장히 황당한게 설명이 너무 심플하다.

음..? 이거 맞나..? 그냥 입력 크기 최종 크기만 알려주면 그 사이에 뭐가 들어가야 하는지는 어떻게 알 수 있는거지..?
이를 통해 확실히 알 수 있는건,
noise z: 100 $\rightarrow$ 200
input y: 10 $\rightarrow$ 1000
x: concat 1000 + 200
Linear: 1200 $\rightarrow$ 784
final sigmoid
이에 따라 인터넷에서 주로 공유되는 방식은 시작전부터 concat 을 하고 시작한다.
class Generator(nn.Module):
# initializers
def __init__(self):
super(Generator, self).__init__()
self.fc1 = self._fc_layer(110, 256)
self.fc2 = self._fc_layer(256, 512)
self.fc3 = self._fc_layer(512, 1200)
self.fc_out = self._fc_layer(1200,784, mode = True)
def _fc_layer(self,in_channels, out_channels, normalize = True, mode = False):
layer = []
layer += [nn.Linear(in_channels, out_channels)]
if mode == True:
#layer += [nn.Sigmoid()]
layer += [nn.Tanh()]
return nn.Sequential(*layer)
else:
#layer + [nn.ReLU()]
layer += [nn.LeakyReLU(negative_slope=0.2, inplace=True)]
if normalize == True:
layer += [nn.Dropout(0.5)]
return nn.Sequential(*layer)
# weight_init
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean, std)
# forward method
def forward(self, input, label):
x = torch.cat((input,label), -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
x = self.fc_out(x)
return x그리고 관례적으로 linear 의 크기를 키운다.
※고민해볼것: Linear (in, out) 의 기준은 어떻게 정하는가?
또다른 방법
class Generator(nn.Module):
# initializers
def __init__(self):
super(Generator, self).__init__()
self.fc1_1 = nn.Linear(100, 256)
self.fc1_1_bn = nn.BatchNorm1d(256)
self.fc1_2 = nn.Linear(10, 256)
self.fc1_2_bn = nn.BatchNorm1d(256)
self.fc2 = nn.Linear(512, 512)
self.fc2_bn = nn.BatchNorm1d(512)
self.fc3 = nn.Linear(512, 1024)
self.fc3_bn = nn.BatchNorm1d(1024)
self.fc4 = nn.Linear(1024, 784)
self.dropout = nn.Dropout(p=0.2)
# weight_init
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean, std)
# forward method
def forward(self, input, label):
x = F.relu(self.fc1_1_bn(self.fc1_1(input)))
y = F.relu(self.fc1_2_bn(self.fc1_2(label)))
x = torch.cat([x, y], 1)
x = F.relu(self.fc2_bn(self.fc2(x)))
x = self.dropout(x)
x = F.relu(self.fc3_bn(self.fc3(x)))
x = self.dropout(x)
x = F.tanh(self.fc4(x))
return x다음과 같이 첫 레이어에서 크기를 동일하게 만든 후 concat 하는 방법도 잘 동작하는 듯 하다.
아무렇게나 크기를 키우고 대충 concat 했었는데, 최대한 관례를 따라가기로 하자.
각종 실험에서 생겼던 가장 큰 의문은 최종 fc layer 이후 drop out 을 한번 더 실행하면 퀄리티가 급작스럽게 떨어졌었다는 것이다.
총 50 에폭 중, 22번째

36번째
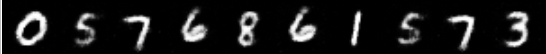
41번째
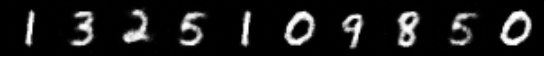
몇가지 실험을 추가해서 학습의 변화를 지켜봐야 겠다.
마지막 layer 후 dropout 추가시
22번째

36번째

41번째

음 학습이 전혀 안된다. 아 근데 생각해보면 마지막 레이어 이후에는 안 붙이는게 당연하다.
지금 내가 한 짓은 마지막 레이어 나왔는데 여기서 또 dropout 을 붙이는 거니까 뭔가 논리상 이상하고 결과도 이상할 것 같기는 하다.
다음 레이어에 넘겨줄 때 학습에 방해를 거는건데, 다음 레이어도 없는데 dropout 하는 것도 말이 안된다..
잘 못 된 실험을 수행 한 것으로 확인.
사실 Discriminator는 논문을 보면 maxout layer 을 사용한다고 되어 있는데, 잘 모르겠다 대부분의 구현을 참고해보면 그렇게 구현한 곳이 없다. 보통 linear layer 로 구현을 하는데, 내가 모르는 insight가 있을 확률이 높다.
class Discriminator(nn.Module):
# initializers
def __init__(self):
super(Discriminator, self).__init__()
self.fc1 = self._fc_layer(794, 1024)
self.fc2 = self._fc_layer(1024, 512)
self.fc3 = self._fc_layer(512, 256)
self.fc_out = self._fc_layer(256, 1, mode = True)
def _fc_layer(self, in_channels, out_channels, normalize = True, mode = False):
layer = []
layer.append(nn.Linear(in_channels, out_channels))
if mode == True:
layer.append(nn.Sigmoid())
return nn.Sequential(*layer)
else:
#layer.append(nn.ReLU())
layer.append(nn.LeakyReLU(negative_slope=0.2, inplace=True))
if normalize == True:
layer.append(nn.Dropout(0.5))
return nn.Sequential(*layer)
# weight_init
def weight_init(self, mean, std):
for m in self._modules:
normal_init(self._modules[m], mean, std)
# forward method
def forward(self, input, label):
x = torch.cat((input,label),-1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
x = self.fc_out(x)
return x이것도 아까와 마찬가지로 linear를 도중에 합칠 수 있다.
# Train
discriminator.train()
g_loss = torch.Tensor([0])
d_loss = torch.Tensor([0])
for epoch in range(parser.n_epochs):
#x는 img
#y는 tensor([3, 6, 1, 9]) # batch
for batch_idx, (x, y) in enumerate(train_loader):
generator.train()
#linear layer 통과를 위해 이미지 차원 resize
#x.shape: (4, 1, 28, 28)
x_flatten = x.view(x.shape[0], -1)
#torch.Size([4, 784])
#Batch size는 유지하면서 다 합쳐서 원한 형태 생성
# 라벨 one-hot encoding
one_hot_label = torch.nn.functional.one_hot(y, num_classes=parser['n_classes'])
#torch.nn.functional.one_hot(torch.tensor([1,2,3,4]), num_classes=10)
# tensor([[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]])
# to GPU
img_torch2vec = x_flatten.type(torch.FloatTensor).cuda()
label_torch = one_hot_label.type(torch.FloatTensor).cuda()
# Adversarial ground truths
valid = torch.ones(parser.batch_size, 1).cuda()
fake = torch.zeros(parser.batch_size, 1).cuda()
# Configure input
real_imgs = img_torch2vec
labels = label_torch
# Train Gen
optimizer_G.zero_grad()
#optimizer 에 parameter를 저장했으므로 zero grad 동작
# Sample noise and labels as generator input
z = torch.randn(parser.batch_size, parser.latent_dim).cuda()
#noise intialization
gen_labels = []
#batch size 4
#random label 4개씩 생성
for randpos in np.random.randint(0, parser.n_classes, parser.batch_size):
gen_labels.append(torch.eye(parser.n_classes)[randpos])
gen_labels = torch.stack(gen_labels).cuda()
# Generate a batch of images
gen_imgs = generator(z, gen_labels)
# Loss measures generator's ability to fool the discriminator
val_output = discriminator(gen_imgs, gen_labels)
g_loss = cross_entropy(val_output, valid)
g_loss.backward()
optimizer_G.step()
# Train Disc
optimizer_D.zero_grad()
validity_real = discriminator(real_imgs, labels)
try:
d_real_loss = cross_entropy(validity_real, valid)
except:
valid = torch.ones(validity_real.shape[0], 1).cuda()
d_real_loss = cross_entropy(validity_real, valid)
# val = output
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
d_fake_loss = cross_entropy(validity_fake, fake)
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
if batch_idx % 100 == 0:
print('{:<13s}{:<8s}{:<6s}{:<10s}{:<8s}{:<9.5f}{:<8s}{:<9.5f}'.format('Train Epoch: ', '[' + str(epoch) + '/' + str(parser['n_epochs']) + ']', 'Step: ', '[' + str(batch_idx) + '/' + str(len(train_loader)) + ']', 'G loss: ', g_loss.item(), 'D loss: ', d_loss.item()))
if epoch % parser.sample_interval == 0:
sample_image(n_row=10, epoch=epoch)학습 과정 코드에서 햇갈릴만한 부분은 최대한 주석을 달아 놓았다.
generator 가 discriminator 를 햇갈리게 하려는 loss 와
discriminator 가 잘 분간하려고 하는 loss 의 통합이다.
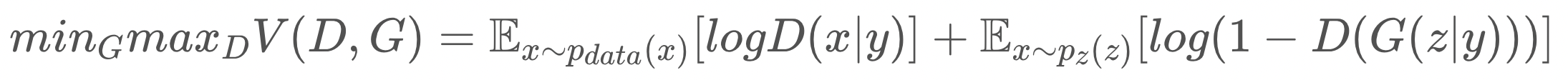
condional Gan 은 Gan 목적 함수에서 |y 만 추가된 것으로 간단하다.
1 -D(G(z|y)) 가 왜 아닌지는 추후 작성할 것
시간이 없다.